Zero-Downtime Deployments with Ansible and EC2? Yes, please!
02 April 2023
Deploying with Ansible is easy. Just copy files over, restart services, and observe a new version of the app. But that might break some connections if some user was just waiting for the server's response. What to do then?
Base infrastructure
An obvious answer is to load balance the traffic between two instances. Let's model our infrastructure. On a diagram it will look like this:
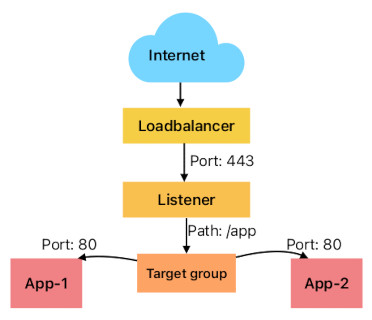
Bottom part of the diagram can be written in Terraform and can look something like this:
resource "aws_instance" "app" {
count = 2
ami = data.aws_ami.amzn2.id # Amazon Linux 2 for ARM
instance_type = "t4g.nano"
key_name = "app-key"
}
# This will be attached to our ELB listener on some path like /app
resource "aws_lb_target_group" "app" {
name = "Apps"
port = 8080
protocol = "HTTP"
vpc_id = data.aws_vpc.default.id # default VPC
health_check {
path = "/"
port = "8080"
protocol = "HTTP"
interval = 10 # Every 10 seconds
}
}
resource "aws_lb_target_group_attachment" "apps" {
count = 2
target_group_arn = aws_lb_target_group.app.arn
target_id = aws_instance.app[count.index].id
}
The whole Terraform configuration can be found in the repository here.
Deployment in practice
Just deploying to both instances in parallel can make access to the app
unavailable for a split second or two. The load balancer is not aware of us
changing anything on the targets. We can do it with serial flag in Ansible and
with a slight sleep, also causing one of the instances to become unhealthy
when the app is down. This approach could work to some extent, when the target
group realizes to not send traffic to unhealthy instances. However, the load
balancer can still direct users to our instance just before we shut the service
down.
Ideally we want to deregister targets before stopping the app and updating the code and then registering them again. So the play in practice would have the following steps:
- Deregister App-1 from the target group.
- Wait until App-1 is drained (unused).
- Update the code and restart/reload the service on App-1.
- Register App-1 to the target group.
- Wait until registration is done and health check passes.
- Repeat steps 1-5 for App-2.
Our main playbook will look like this:
- hosts: apps
become: yes
serial: 1
vars:
deploy_dir: /opt/app
tasks:
- import_tasks: tasks/deregister.yml
- import_tasks: tasks/deploy.yml
- import_tasks: tasks/reload-service.yml
- import_tasks: tasks/register.yml
So how to implement these steps? Reloading service and deploying the app will be very specific to the app we want to update. But deregistering and registering the instance should be similar for each solution on EC2.
Despite Ansible has a module for interacting with AWS, there's no such for EC2
Target Groups. For that we can use AWS SDK, such as boto3 for Python or just
AWS CLI. We can also utilize raw HTTP requests but that's more complex and
requires more work than just using a library.
Deregistering and registering
For EC2 we first have to setup a role with attached policy that will allow us to
deregister or register an instance from a target group. It's also possible to do
this on the host of the playbook using connection: local but let's keep the
structure simple and make our instances be able to register and deregister
themselves similar to microservices. The policy will look like this:
resource "aws_iam_policy" "app-target-group-policy" {
name = "app-target-group-policy"
policy = <<-EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"elasticloadbalancing:RegisterTargets",
"elasticloadbalancing:DeregisterTargets"
],
"Resource": "${aws_alb_target_group.apps.arn}"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"elasticloadbalancing:DescribeTargetGroups",
"elasticloadbalancing:DescribeTargetHealth"
],
"Resource": "*"
}
]
}
EOF
}
Where aws_lb_target_group.app.arn is the ARN of our target group from above.
This is just the policy, see
this file
in the repository for the full IAM role recipe.
So once we have a role with the policy attached, we can test it on our machines by installing AWS CLI and running the following command:
$ yum install awscli # if you use AmazonLinux2, you can also use any other SDK
$ aws sts get-caller-identity
{
"Account": "999901234567",
"UserId": "AROA6RABCDEFGHJKL1234:i-0abcde12345678901",
"Arn": "arn:aws:sts::999901234567:assumed-role/app-role/i-0abcde12345678901"
}
Once we have the permissions to modify target groups from within our instance, let's write tasks that will:
- get the IMDS token,
- get the instance ID,
- deregister instance from the target group,
- wait until the instance is deregistered.
This will be our tasks/deregister.yml file:
---
- name: Get IMDSv2 token
uri:
url: http://169.254.169.254/latest/api/token
headers:
X-aws-ec2-metadata-token-ttl-seconds: 21600
method: PUT
return_content: yes
register: token
- name: Get instance ID
uri:
url: http://169.254.169.254/latest/meta-data/instance-id
headers:
X-aws-ec2-metadata-token: "{{ token.content }}"
method: GET
return_content: yes
register: instance_id
- name: Deregister instance from ELB
shell:
cmd: >-
aws elbv2 deregister-targets --region=eu-central-1
--target-group-arn "{{ target_group_arn }}"
--targets "Id={{ instance_id.content }}"
- name: Wait for target to become unused
shell:
cmd: >-
aws elbv2 describe-target-health --region=eu-central-1
--target-group-arn "{{ target_group_arn }}"
--targets "Id={{ instance_id.content }}"
register: health
until: "( health.stdout | from_json ).TargetHealthDescriptions[0].TargetHealth.State == 'unused'"
changed_when: false
retries: 10
delay: 10
The last task will wait up to 100 seconds for the instance to become unused. We
can control how long the draining should take on AWS side by adding an argument
to aws_lb_target_group resource in Terraform:
resource "aws_lb_target_group" "app" {
name = "Apps"
port = 8080
deregistration_delay = 60 # This will make the target drain for 60 seconds
...
Be sure to adapt this value to your use case. It should be as long as the longest request your app can handle before timeout.
Registration will look almost the same. We already have the instance ID so we
can skip first two tasks. We will just use aws elbv2 register-targets and wait
until the .TargetHealth.State is equal to healthy. Control the speed of the
instance reaching this status by changing the health_check block parameters.
Complete file with changes is
available here.
End Result
We can test how effective our deployment is by running the playbook alongside a loop that will send requests constantly to our app.
$ for i in {1..10000}; do\
curl https://test.mydomain.net/apps; echo; sleep 0.1;\
done
# If you don't have a domain, use load balancer's DNS name with k flag in curl
We can also observe graphs in AWS console. It's visible that some instances
become unhealthy but there's no errors in the curl loop. Observe also how the
reported hostname becomes constant when one of the instances is deregistered and
soon, when Ansible starts deploying again, the hostname changes to the second
instance.
If we remove the deregistration and registration routines, we get a lot of 502 before the load balancer reacts to the healthcheck.