Profiling AWS DocumentDB
31 October 2023
MongoDB, a NoSQL database used since a long time as the primary database of many web applications. AWS offers a managed solution for MongoDB called DocumentDB. It is highly available, easy to scale read capacity horizontally and the storage can scale automatically. However, even with those features, we are still likely to hit a bottleneck here or there when querying the database. Today, we will look at the profiling feature of DocumentDB that can help us identify queries that take a long time.
Creating a DocumentDB parameter group
Before we start we need to create a parameter group that will enable profiling for our database (and TLS as well). We will use Terraform/OpenTofu for that. I assume that you will prepare provider configuration and credentials yourself. Our profiler should trigger as soon as possible, which is when a query takes more than 50ms. We will also sample every query, as we don't have much traffic.
resource "aws_docdb_cluster_parameter_group" "profiler-params" {
family = "docdb4.0"
name = "param-group-profiler"
description = "Parameter group with TLS and profiling enabled"
parameter {
name = "tls"
value = "enabled"
}
parameter {
name = "profiler"
value = "enabled"
}
parameter {
name = "profiler_sampling_rate"
value = "1.0"
}
parameter {
name = "profiler_threshold_ms"
value = "50"
}
}
Configuring VPC
Next up let's define a VPC that will be used by our DocumentDB cluster. I will
use here data sources to get the default VPC and subnets. For production, it's
advised to use a dedicated VPC and maintain full control over it. We will also
define a subnet group for the DocumentDB, so it knows where to launch instances.
data "aws_vpc" "default" { default = true }
data "aws_subnet" "public-a" {
vpc_id = data.aws_vpc.default.id
availability_zone = "eu-west-1a"
}
data "aws_subnet" "public-b" {
vpc_id = data.aws_vpc.default.id
availability_zone = "eu-west-1b"
}
resource "aws_security_group" "documentdb" {
vpc_id = data.aws_vpc.default.id
name = "mycluster-sg"
description = "Allows VPC access to DocumentDB cluster"
ingress {
from_port = 27017
to_port = 27017
protocol = "tcp"
cidr_blocks = [data.aws_vpc.default.cidr_block]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
ipv6_cidr_blocks = ["::/0"]
}
}
resource "aws_docdb_subnet_group" "subnets" {
subnet_ids = [data.aws_subnet.public-a.id, data.aws_subnet.public-b.id]
name = "default-ab"
}
Apply these things, they should be pretty straightforward and fast.
Starting a cluster and instance
Now it's the time for the main guest of today's episode. We will create a
DocumentDB cluster with a single instance. The cluster will use the previously
defined parameter group as well as subnet and security groups. The password will
be also stored here, so we can use it later to connect to the database. In real
world scenario, you should add lifecycle clause to Terraform to ignore
master_password changes and rotate the password to something complex.
resource "aws_docdb_cluster" "mycluster" {
cluster_identifier = "mycluster"
# Network settings
db_subnet_group_name = aws_docdb_subnet_group.subnets.id
vpc_security_group_ids = [aws_security_group.documentdb.id]
# Cluster settings
engine = "docdb"
engine_version = "4.0.0"
master_username = "administrator"
master_password = "Staple3-Battery2-Horse1"
enabled_cloudwatch_logs_exports = ["profiler"]
db_cluster_parameter_group_name = aws_docdb_cluster_parameter_group.profiler-params.id
apply_immediately = true
}
resource "aws_docdb_cluster_instance" "myinstance" {
cluster_identifier = aws_docdb_cluster.mycluster.id
instance_class = "db.t4g.medium"
engine = "docdb"
identifier = "myinstance"
}
output "mongo_url" {
value = "${aws_docdb_cluster.mycluster.master_username}:${aws_docdb_cluster.mycluster.master_password}@${aws_docdb_cluster.mycluster.endpoint}:${aws_docdb_cluster.mycluster.port}"
sensitive = true
}
Because we enabled profiling it's also important that we enable logs export to CloudWatch from the cluster configuration. Then after we perform the tests we will see the slow queries. To get the connections string, type the following:
$ terraform output mongo_url
Creating an instance to run tests
DocumentDB is deployed inside VPC. That means we need to have a machine inside it. We will use a simple EC2 instance for that. I created one that is managed by SSM because of safety and convenience. You can use plain SSH for this.
data "aws_ssm_parameter" "AmazonLinux" {
name = "/aws/service/ami-amazon-linux-latest/al2023-ami-kernel-6.1-arm64"
}
resource "aws_security_group" "all-egress" {
name = "all-egress"
vpc_id = data.aws_vpc.default.id
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
ipv6_cidr_blocks = ["::/0"]
}
# Add ingress for SSH here if you want SSH from your PC
}
... # Skipped SSM role and profile config, refer to GitHub repo
resource "aws_instance" "TestInstance" {
ami = data.aws_ssm_parameter.AmazonLinux.value
instance_type = "t4g.nano"
iam_instance_profile = aws_iam_instance_profile.test-ssm.name # Optional SSM
subnet_id = data.aws_subnet.public-a.id
vpc_security_group_ids = [aws_security_group.all-egress.id]
}
After boot (you can use user data for it), we need to install some tools. These are Python PIP, MongoDB client library, requests library and Amazon RDS public certificate (despite RDS in the name, DocumentDB uses the same).
$ sudo yum install -y python3-pip
$ sudo pip3 install pymongo requests
$ sudo mkdir -p /usr/local/share/ca-certificates/
$ sudo wget https://truststore.pki.rds.amazonaws.com/global/global-bundle.pem -O /usr/local/share/ca-certificates/rds.pem
$ sudo chmod 0644 /usr/local/share/ca-certificates/rds.pem
Time for testing
Now we have to somehow put pressure on the DocumentDB. t4g.medium is a pretty
strong instance so the data has to be large. I created a simple Python script
available
in the repo here
that will insert 5000 student IDs, 1000 test questions and 5'000'000 answers
(every student for every question). Already inserting these records generates
enough load on the database to trigger the profiler. Be sure to set the correct
environment variable with the connection string.
$ export MONGO_URL=<output of terraform output mongo_url>
$ python3 insert_plenty.py
After you load all the records (this can take a good minute), try querying the database with another script. This one will do some joins in aggregate. The query script is available here.
Watching the profiler
Now let's go to the AWS Console and open CloudWatch. You should find a log group
/aws/docdb/mycluster/profiler. Inside it, you will find a log stream with
all the queries that were slow.
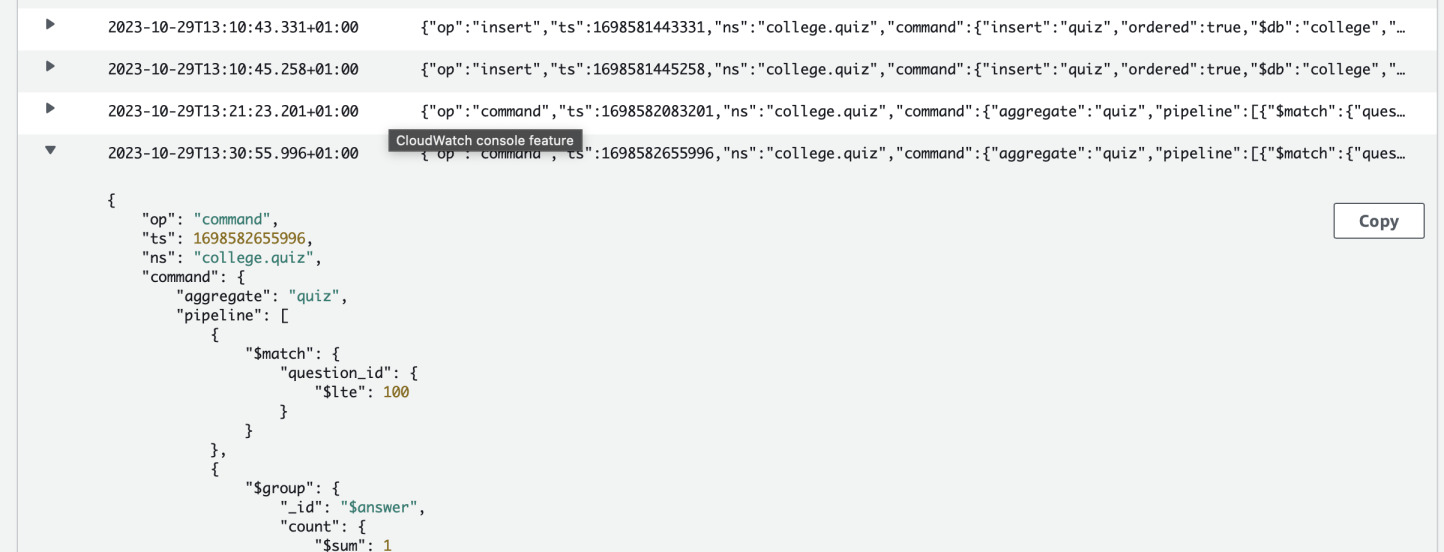
The advantage of this solution is that setting this up is very easy and no need for any additional software. It's not the most advanced solution but a good starting point to know what functions of your application are putting too much pressure on the database. You can adjust the profiler to your needs by changing threshold of slow queries.