Daily Git diff into S3
29 July 2024
One thing I need for a future project is a way to collect all the changes in a
Git repository (on a specific branch) and store them in some place such as S3
bucket. I thought about it extensively and came with such a solution you can
find on the diagram below. Firstly, we have a CodeCommit repository (for
simplicity but it can be GitHub or anything else). A task in ECS will clone the
repository, create a diff on the develop branch between HEAD and last run and
store it in S3. The commit hash will be stored in SSM Parameter Store (DynamoDB
would be too much complexity or even cost). So for run n+1-th the hash found
in SSM Parameter will be HEAD of the n-th run. In case the parameter does
not exist, we will use a generated hash of empty repository (will describe it
soon).
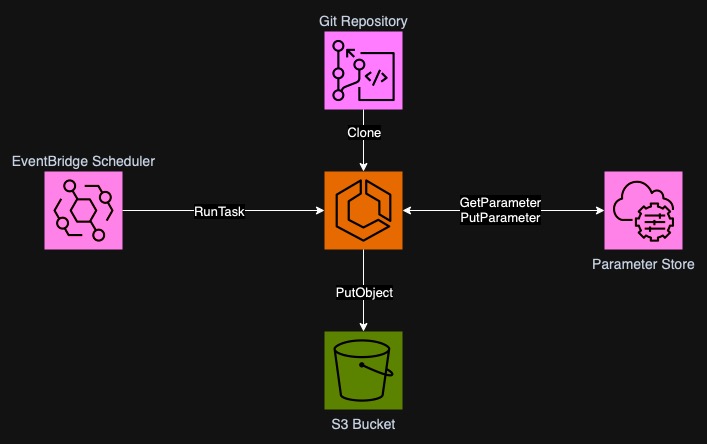
The task will be scheduled by EventBridge scheduler. ECS Task, VPC, S3, ECR and Docker image will all be prepared already in the infrastructure. The event will only need to trigger the task with appropriate environment variables.
I updated this project with example on how to connect to GitHub! Find the new post here
Base infrastructure
I will skip the code for network infrastructure as it's available in the repository for this project. I created a VPC with one public subnet, Internet Gateway and a default security group that allows full outbound traffic, so this is a pretty standard setup. I also created an empty ECS cluster with a name - it also doesn't need any special parameters. I also created a CodeCommit repository with a variable name. This is also nothing difficult. This will be the repository where we will store our code for creating diffs. It can also act as a mirror for GitHub, Bitbucket or GitLab.
# This is all the networking infrastructure
# See https://github.com/ppabis/git-diff-to-s3/tree/main/vpc
module "vpc" {
source = "./vpc"
}
resource "aws_ecs_cluster" "cluster" {
name = "GitDiffCluster"
}
variable "repo_name" {
description = "The name of the repository"
type = string
}
resource "aws_codecommit_repository" "CodeCommitRepo" {
repository_name = var.repo_name
}
Next, I created a module, ecr, that will hold a new Docker image that we will
build and push to the ECR repository. The image will pack the script that will
be called on startup and read environment variables. But for now we will keep it
simple and just create an ECR repository with some outputs.
resource "aws_ecr_repository" "ecr_image" {
name = "pabiseu/gitdiff"
force_delete = true
}
output "repository" {
value = aws_ecr_repository.ecr_image.repository_url
}
output "repository_arn" {
value = aws_ecr_repository.ecr_image.arn
}
One very important thing is to create correct IAM permissions. For ECS we need
two roles: task role and execution role. The execution role will probably only
need ECR access to pull the image. The task role on the other hand is what our
application needs to run - so we will need CodeCommit read access, S3 write and
SSM read and write access. I will also add logs configuration so it's easier to
debug in case something happens. I placed the following files in another iam
module.
Task role
The first file is the task role. It will allow the ECS container to perform calls to AWS - read/write SSM Parameters, clone CodeCommit repository and write logs.
resource "aws_iam_role" "TaskRole" {
name = "ECS_TaskRole"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [ {
Effect = "Allow"
Principal = { Service = "ecs-tasks.amazonaws.com" }
Action = "sts:AssumeRole"
} ]
})
}
data "aws_caller_identity" "me" {}
data "aws_iam_policy_document" "TaskRolePolicy" {
statement {
actions = [
"logs:CreateLogStream",
"logs:PutLogEvents"
]
resources = [ "${aws_cloudwatch_log_group.git_diff_log_group.arn}:*" ]
}
statement {
actions = [
"ssm:GetParameter",
"ssm:PutParameter",
"ssm:DeleteParameter"
]
resources = [ "arn:aws:ssm:eu-west-1:${data.aws_caller_identity.me.account_id}:parameter/git-diff/*" ]
}
statement {
actions = [ "codecommit:GitPull" ]
resources = [ var.codecommit_repo_arn ]
}
}
resource "aws_iam_role_policy" "TaskRolePolicy" {
role = aws_iam_role.TaskRole.id
policy = data.aws_iam_policy_document.TaskRolePolicy.json
}
Execution role
The second file is execution role. It uses the same assume/trust policy as the task role. This one will perform the ECS meta operations such as pulling and running the Docker image from ECR and creating the first stream of CloudWatch Logs.
resource "aws_iam_role" "ExecutionRole" {
name = "ECS_ExecutionRole"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [ {
Effect = "Allow"
Principal = { Service = "ecs-tasks.amazonaws.com" }
Action = "sts:AssumeRole"
} ]
})
}
data "aws_iam_policy_document" "ExecutionRolePolicy" {
statement {
actions = [
"logs:CreateLogStream",
"logs:PutLogEvents"
]
resources = [ "${aws_cloudwatch_log_group.git_diff_log_group.arn}:*" ]
}
statement {
actions = [ "ecr:GetAuthorizationToken" ]
resources = [ "*" ]
}
statement {
actions = [
"ecr:BatchCheckLayerAvailability",
"ecr:GetDownloadUrlForLayer",
"ecr:GetRepositoryPolicy",
"ecr:DescribeRepositories",
"ecr:ListImages",
"ecr:BatchGetImage",
"ecr:DescribeImages"
]
resources = [ var.ecr_repository_arn ]
}
}
resource "aws_iam_role_policy" "ExecutionRolePolicy" {
role = aws_iam_role.ExecutionRole.id
policy = data.aws_iam_policy_document.ExecutionRolePolicy.json
}
Based on the above policies I created two roles that will be attached to the ECS task. For S3, we will specify the permissions in the bucket policy allowing our task role to perform writes. The policies above also refer to a CloudWatch Log group - 4 lines below.
resource "aws_cloudwatch_log_group" "git_diff_log_group" {
name = "/aws/ecs/GitDiffCluster"
retention_in_days = 7
}
As variables you need to only provide ECR and CodeCommit repositories ARNs. Or you can hardcode them or even switch to attribute-based access policies.
Docker image and ECR repository
The main part of this project is of course Docker image that will perform the
activities. We will start with a Bash script that will be the entrypoint of our
image. In a new file git-diff.sh I put the following contents. I will describe
what each part does in a moment.
#!/bin/bash
if [ -z "$GIT_REPO" ]; then
echo "GIT_REPO is not set. Exiting."
exit 1
fi
if [ -z "$PARAMETER_NAME" ]; then
echo "PARAMETER_NAME is not set. Exiting."
exit 1
fi
if [ -z "$RESULTS_BUCKET" ]; then
echo "RESULTS_BUCKET is not set. Exiting."
exit 1
fi
RESULTS_BUCKET=${RESULTS_BUCKET%/} # Strip the last slash if the path has it
LAST_COMMIT=$(aws ssm get-parameter --name $PARAMETER_NAME --query Parameter.Value --output text || true)
if [ -z "$LAST_COMMIT" ]; then
# Empty tree hash, see https://stackoverflow.com/a/73793394
LAST_COMMIT=$(git hash-object -t tree /dev/null)
fi
git config --global credential.helper '!aws codecommit credential-helper $@'
git config --global credential.UseHttpPath true
git clone $GIT_REPO /tmp/repo
cd /tmp/repo
git diff $LAST_COMMIT..HEAD > /tmp/changes.diff
PREV_COMMIT=${LAST_COMMIT:0:7} # First 7 characters of the hash
CURRENT_COMMIT=$(git rev-parse --short HEAD)
NOW_DATE=$(date -u +"%Y-%m-%d-%H%M")
S3_KEY="${NOW_DATE}_${PREV_COMMIT}-${CURRENT_COMMIT}.diff" # Example: 2024-06-06-2137_8fbbe55-6b11430.diff
aws s3 cp /tmp/changes.diff s3://$RESULTS_BUCKET/$S3_KEY
aws ssm put-parameter --name $PARAMETER_NAME --value $(git rev-parse HEAD) --type String --overwrite
The script is quite simple despite its length. First we just check if all the environment variables are set so that our script knows which repository to clone, where to store the results and where to keep track of last processed commit hash. We also strip the last slash of S3 path in case you want to specify it.
Next we check if the parameter with name taken from PARAMETER_NAME exists in
SSM Parameter Store. In case not, the aws ssm get-parameter command will raise
and error so we have to neutralize it with || true. The default value for
LAST_COMMIT would thus be an empty Git tree.
In order for our container to access CodeCommit using its IAM credentials, we
need to specify a credential helper for Git in the configuration. Because of the
fact we will use HTTP URL for cloning. Clone the repo and create diff between
LAST_COMMIT and current state. It will use the branch marked as default. Then
we just format the results file name with all these variables and copy it to S3.
At the final step we need to save last processed commit (aka HEAD) to SSM
Parameter Store.
Now we can proceed to creating our Dockerfile. It will be based on the AWS CLI
image and we will install git.
FROM amazon/aws-cli:latest
RUN yum install -y git
COPY git-diff.sh /usr/local/bin/git-diff
RUN chmod +x /usr/local/bin/git-diff
ENTRYPOINT [ "/bin/sh" ]
CMD ["-c", "git-diff"]
I want the process of building the image and pushing it to ECR be as automated
as possible and tied to this project so I will use kreuzwerker/docker provider
that will build the image using my local Docker daemon and I will use custom
commands to push it to ECR - as I need to log in and my current AWS credentials
should also have permissions to do so.
resource "aws_ecr_repository" "ecr_image" {
name = "pabiseu/gitdiff"
force_delete = true
}
resource "docker_image" "ecr_image" {
name = "${aws_ecr_repository.ecr_image.repository_url}:latest"
build {
context = path.module
dockerfile = "./Dockerfile"
}
}
resource "null_resource" "docker_push" {
depends_on = [docker_image.ecr_image]
lifecycle { replace_triggered_by = [docker_image.ecr_image] }
provisioner "local-exec" {
# Select your own region
command = "aws ecr get-login-password --region eu-west-1 | docker login --username AWS --password-stdin ${aws_ecr_repository.ecr_image.repository_url}"
}
provisioner "local-exec" {
command = "docker push ${aws_ecr_repository.ecr_image.repository_url}:latest"
}
}
output "repository" { value = aws_ecr_repository.ecr_image.repository_url }
output "repository_arn" { value = aws_ecr_repository.ecr_image.arn }
AWS recently announced
that the service deployments will internally keep the hash of the image instead
of always pulling latest to not make pushing to ECR break running services.
However, it doesn't apply to single tasks like this one. In order to update
the image we will need to use tofu taint module.ecr.docker_image.ecr_image.
Another approach is to use timestamp in locals as the image tag but then the
image will be updated with every tofu apply.
S3 bucket for the results
Now I will briefly go through what we need to do with the S3 bucket in order for
it to store the results. I will just create a bucket with some name (I use
hashicorp/random provider to keep the bucket names unique) and add a bucket
policy that will allow our ECS task to write.
resource "random_string" "suffix" {
length = 6
special = false
upper = false
}
resource "aws_s3_bucket" "results_bucket" {
bucket = "git-diff-results-bucket-${random_string.suffix.result}"
}
data "aws_iam_policy_document" "allow_task_role_put" {
statement {
actions = [ "s3:PutObject" ]
resources = [ "${aws_s3_bucket.results_bucket.arn}/*" ]
principals {
type = "AWS"
identifiers = [ module.iam.task_role_arn ]
}
}
statement {
actions = [
"s3:ListBucket",
"s3:GetBucketLocation"
]
resources = [ aws_s3_bucket.results_bucket.arn ]
principals {
type = "AWS"
identifiers = [ module.iam.task_role_arn ]
}
}
}
resource "aws_s3_bucket_policy" "allow_task_role_put" {
bucket = aws_s3_bucket.results_bucket.bucket
policy = data.aws_iam_policy_document.allow_task_role_put.json
}
Task Definition
I will create a simple task definition that contains a single container. Some of the parameters can be set using Terraform resource but not everything. Thus I split it into two parts: the task definition itself and container definitions in a separate YAML (as this parameter takes a JSON string).
resource "aws_ecs_task_definition" "GitDiffTask" {
family = "GitDiffTask"
network_mode = "awsvpc"
cpu = 1024
memory = 2048
requires_compatibilities = ["FARGATE"]
execution_role_arn = module.iam.execution_role_arn
task_role_arn = module.iam.task_role_arn
runtime_platform {
operating_system_family = "LINUX"
cpu_architecture = "ARM64"
}
container_definitions = jsonencode(yamldecode(
templatefile(
"${path.module}/taskdef.yaml",
{
image = "${module.ecr.repository}:latest",
results_bucket = aws_s3_bucket.results_bucket.bucket,
log_group = module.iam.log_group_name,
region = var.region
}
)
))
}
The first part contains high-level configuration such as roles used for the task
and hardware assignment. If you are building the project on an Intel-based
computer, you probably should change cpu_architecture to X86_64 as we build
the image locally. Then we load container_definitions from a YAML template
where we also fill some variables as they can change based on other resources'
configuration. The taskdef.yaml will look the following:
---
- image: "${image}"
name: "git"
logConfiguration:
logDriver: "awslogs"
options:
awslogs-group: "${log_group}"
awslogs-region: "${region}"
awslogs-stream-prefix: "diff"
It's very simple definition that has only one container with specified image and logging configuration that pushes logs to CloudWatch.
EventBridge Schedule
I use new EventBridge Scheduler to trigger the task. I created a new module that
contains both role for this schedule and the rule itself. The role for this
schedule is quite restrictive - it shows how you can keep the permissions as
little as possible. The policy requires ecs:RunTask permission. The resource
to specify is ARN of task definition - it can be a specific version or ARN with
* to allow any version. I want to also limit cluster where the task can be
run. The schedule also needs to pass the roles for both execution and task.
resource "aws_iam_role" "ScheduleRole" {
name = "GitDiffScheduleRole"
assume_role_policy = <<-EOF
{
"Version": "2012-10-17",
"Statement": [ {
"Effect": "Allow",
"Principal": { "Service": "scheduler.amazonaws.com" },
"Action": "sts:AssumeRole"
} ]
}
EOF
}
data "aws_iam_policy_document" "ScheduleRolePolicy" {
statement {
actions = [ "ecs:RunTask" ]
resources = [ var.task_definition_arn ]
condition {
test = "StringEquals"
variable = "ecs:cluster"
values = [ var.cluster_arn ]
}
}
statement {
actions = [ "iam:PassRole" ]
resources = [
var.task_role_arn,
var.execution_role_arn
]
condition {
test = "StringEquals"
variable = "iam:PassedToService"
values = [ "ecs-tasks.amazonaws.com" ]
}
}
}
resource "aws_iam_role_policy" "ScheduleRolePolicy" {
role = aws_iam_role.ScheduleRole.id
policy = data.aws_iam_policy_document.ScheduleRolePolicy.json
}
Using this role we can create a schedule in EventBridge. As I create this in a separate module, we also need to define a lot of variables - both of values that have to be passed to this IAM policy and to the task parameters. Following is the list of variables that are needed for schedule and role permissions:
cluster_arntask_definition_arn- task definition with or without version (with*)task_role_arnexecution_role_arnsubnet_idsg_id- security group IDcluster_nametask_definition_arn_version- task definition with versionrepo_url- HTTP URL to clone the repositorybucket_name- S3 bucket name or name with prefix pathparameter_name- name of SSM parameter (starts with/git-diff/)
The schedule rule needs to be formatted correctly as ECS tasks requires very complex input parameter configuration. We will start with the basic stuff like when to run the task, what role to use. At the end the input to the target will be a JSON object with many parameters. We need to specify network configuration, on which cluster to run, what environment variables to set for the script.
resource "aws_scheduler_schedule" "schedule" {
name = "GitDiffSchedule"
flexible_time_window { mode = "OFF" }
schedule_expression = "cron(0 0 * * ? *)" # Run every day at midnight
target {
arn = "arn:aws:scheduler:::aws-sdk:ecs:runTask"
role_arn = aws_iam_role.ScheduleRole.arn
input = jsonencode({
TaskDefinition = var.task_definition_arn_version,
Cluster = var.cluster_name,
LaunchType = "FARGATE",
NetworkConfiguration = {
AwsvpcConfiguration = {
Subnets = [var.subnet_id],
SecurityGroups = [var.sg_id],
AssignPublicIp = "ENABLED"
}
},
Overrides = {
ContainerOverrides = [{
Name = "git",
Environment = [
{ Name = "GIT_REPO", Value = var.repo_url },
{ Name = "RESULTS_BUCKET", Value = var.bucket_name },
{ Name = "PARAMETER_NAME", Value = var.parameter_name }
]
}]
}
}) # End of jsonencode
}
}
Committing to the repository
As now we have all the infrastructure and task prepared, we can test it. I
changed the schedule to rate(10 minutes) for a while to see task runs sooner.
Then I quickly put a new file in the repository. One thing worth noting is that
it's recommended to have something in the repo already before enabling the
schedule as if there's nothing, the HEAD doesn't exist and thus it will break
the script - you will then need to delete the SSM parameter to fix future runs.
My first commit was to create a readme file. Then I waited for the first diff to
be produced, then committed changes to readme and created .editorconfig.
That's how the diffs look like.
First diff
diff --git a/README.md b/README.md
new file mode 100644
index 0000000..100b938
--- /dev/null
+++ b/README.md
@@ -0,0 +1 @@
+README
\ No newline at end of file
Second diff
diff --git a/.editorconfig b/.editorconfig
new file mode 100644
index 0000000..3277b7b
--- /dev/null
+++ b/.editorconfig
@@ -0,0 +1,23 @@
+# Root .editorconfig file indicating that it is the top-most .editorconfig file
+root = true
+
+# Common settings for all files
+[*]
+end_of_line = lf
+insert_final_newline = true
+charset = utf-8
+trim_trailing_whitespace = true
+
+# Specific settings for YAML files
+[*.yaml]
+indent_style = space
+indent_size = 2
+
+[*.yml]
+indent_style = space
+indent_size = 2
\ No newline at end of file
diff --git a/README.md b/README.md
index 100b938..d390fd0 100644
--- a/README.md
+++ b/README.md
@@ -1 +1,4 @@
-README
\ No newline at end of file
+Project repository
+==================
+Please apply .editorconfig and follow guidelines of
+formatting the files.
\ No newline at end of file
Using this project you can collect diffs every day and see what changes you or
your team did to the project. This can be then analyzed in terms of quality,
agility or be fed into a machine learning model for further analysis. One thing
that I myself would like to change is to suppress the No newline message but
unfortunately it's not an option in Git - we would need to use grep -v for
that in our git-diff.sh script. However,
according to StackOverflow
it's a good practice to have a new line at the end.
git diff $LAST_COMMIT..HEAD | grep -v "\\ No newline at the end of file" > /tmp/changes.diff