LLM Agents with Ell
20 October 2024
Ell is a quite new Python library that is similar to LangChain. In my opinion it feels simpler to use but is not so featureful. It is mostly useful as a higher level API on top of LLM providers (such as OpenAI or Anthropic) and creation of agentic tools - functions that can be used by a LLM. But the main selling point is that it can store all the requests and responses in a database, that can be later viewed in Ell Studio - a GUI running in your browser that shows dependency graph with details of each prompt and tool, while also keeping track of changes to these pieces. This makes Ell an ultimate tool for prompt engineering. Each prompt and tool is represented as Python function and the database keep tracks of functions' signature and implementation changes. Moreover, the docs part of the function is the system message which makes it very well blended into the Python code. To mark the function as either prompt/chat or a tool, you can use Python decorators.
Basic example
I will show you a simple example on how to connect Ell to OpenAI to use GPT. The process for Claude will be similar. I will cover other providers later on as they are not directly included in Ell so far and you need some custom configuration.
import ell
@ell.simple( model="gpt-4o-mini", temperature=0.7 )
def name_meaning(name: str) -> str:
"""
You are a chatbot that tells the meaning of person's name in a funny way.
"""
return f"The person who approached you is named {name}."
if __name__ == '__main__':
print( name_meaning("Mordecai") )
This is a prompt that uses GPT-4o-mini. It contains the system prompt of
You are a chatbot that tells the meaning of person's name in a funny way. The
user message sent to the LLM will be
The person who approached you is named Mordecai. In order to run this example,
you will need an API key from OpenAI. Log in to OpenAI, go to
Projects, create a new
project and create an API key in the new project for yourself. Restrict it to
Read on Models and Write on Model capabilities. Store the key in a
safe place such as password manager. Of course you also need some credits or
payment method 😄 - I always top up my account with $10 worth of credits so that
I am on a safe side.
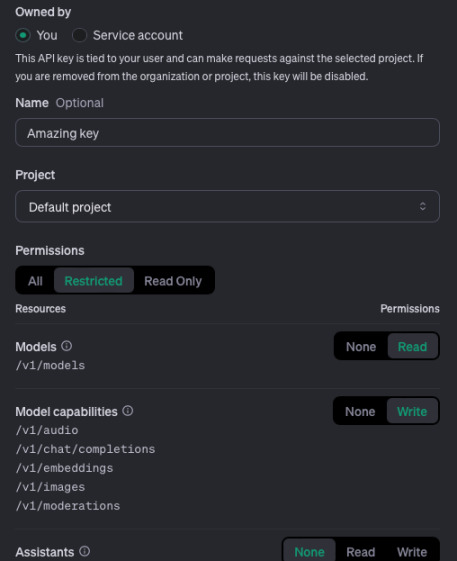
Now as you have saved the key into a password manager or something, you can run
the example. Assuming you have Python3 with venv installed globally, we will
create a new virtual environment and install ell. Save the above example in a
file called example.py and run the following commands:
$ python3 -m venv venv
$ source venv/bin/activate # Creating a virtual environment
$ pip install ell-ai
$ pip install "ell-ai[all]" # Install ell
$ read -s OPENAI_API_KEY # Paste the API key after running this command
$ export OPENAI_API_KEY
$ python3 example.py # Run
Ah, Mordecai! The name that sounds like a fancy dish you’d order at a five-star restaurant but ends up being just a really intense salad!
Storing and browsing prompts
As stated before, one of great Ell's capabilities is its prompt browser. Storing all the calls made by Ell, responses and changes to the functions is super easy and straightforward. Just add this single line at the beginning of the main file. Then all the functions marked by any of Ell's decorators will be recorded.
import ell
ell.init(store='./log', autocommit=True)
@ell.simple( model="gpt-4o-mini", temperature=0.7 )
def name_meaning(name: str) -> str:
...
It should create a new directory called log with a database of calls. Try it
out! Then try changing the function signature by adding something like example
below and running the program again.
import ell
ell.init( store="./log", autocommit=True )
@ell.simple( model="gpt-4o-mini", temperature=0.7 )
def name_meaning(name: str, age: int) -> str:
"""
You are a chatbot that tells the meaning of person's name in a funny way.
Adapt your response to the person's age.
"""
return f"The person who approached you is named {name}. Their age is {age}."
if __name__ == '__main__':
print(name_meaning("Mordecai", 20))
print(name_meaning("Mordecai", 5))
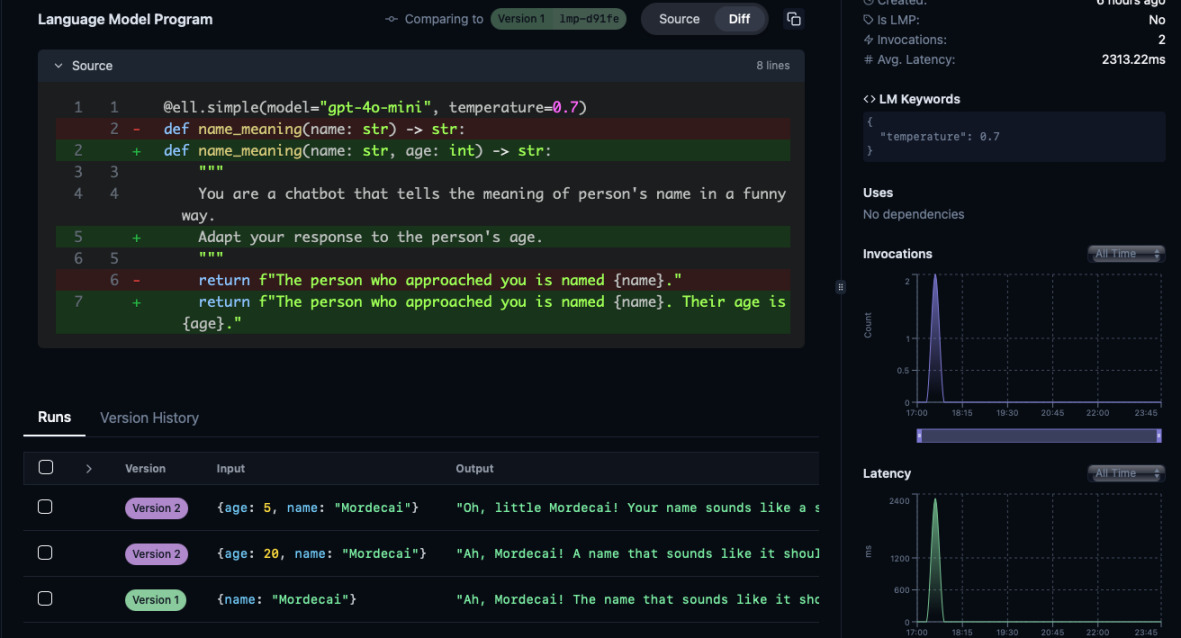
Now you can run Ell Studio on this database. It will serve a web page on
localhost and port 5555 where you can browse the calls and responses in your
browser.
$ ell-studio --storage-dir log
INFO: Uvicorn running on http://127.0.0.1:5555 (Press CTRL+C to quit)
2024-10-10 17:39:29 INFO ] Database file found: log
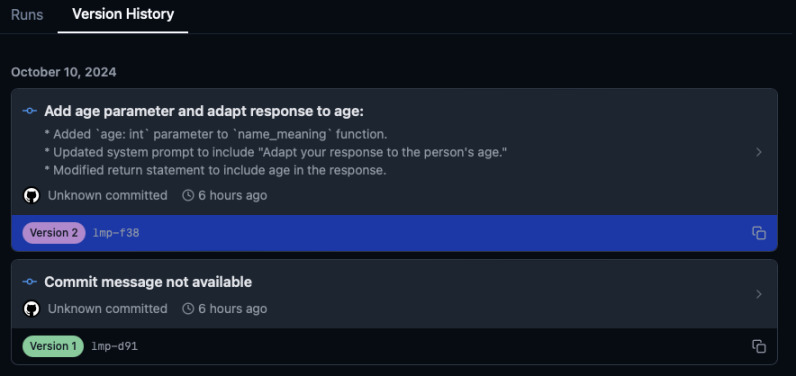
Open the browser and go to http://localhost:5555 to see all the functions that
were called. What is more, the database tracks changes to the functions and
their signatures (stylized as Git commits). You can easily compare the prompts
and see the behavior change.
Defining tools for agents
Defining tools for agents is almost as easy as defining prompts. You just need
to use @ell.tool decorator on the function that is supposed to be a tool. Then
on the prompt function you use @ell.complex decorator and specify the list of
tools to use. However, remember, each tool increases used tokens. Although for
the modern models it shouldn't be a problem. But if you plan to retrieve entire
websites and put it into the conversation, you need to remember about managing
the context window size. GPT-4o and GPT-4o-mini has 128k tokens context window
so it seems to be quite large but creating an entire backend service with GPT-4o
instead of business logic doesn't seem like a reasonable idea.
One of the most difficult things for LLMs is comparing two numbers (or at least
it used to be). The most popular one in Is 9.11 bigger than 9.9?. However, as
this trivial problem was recently patched, let's bump the difficulty to use some
trigonometry. From my tests, it is confusing enough for GPT-4o-mini where it
changes the answer every other time with temperature of 0.5 without help of
any tools.
The tools in Ell are defined as Python functions where the docstring is the
description of what the tool does (it is passed to the LLM) as well as each
argument should be marked with pydantic.Field with a description of what each
argument is supposed to do.
import ell
import math
from pydantic import Field
@ell.tool()
def sin(angle: float = Field(description="Angle in degrees.")) -> str:
"""Returns a value of sin(angle) with up 10 decimal places. For example sin(30) = 0.5."""
value = math.sin(math.radians(angle))
return f"{value:.10f}"
Now we can pass this tool to the prompt. It will be automatically injected when sending the request to the API. Our new prompt function will return a full list of messages because each request to use a tool is being responded to us by the LLM as well as each result from a tool is a new user message added to the conversation so that we are not stuck in a loop of the model needing answers from the tools.
from typing import List
@ell.complex(model="gpt-4o-mini", tools=[ sin ], temperature=0.5)
def math_assistant(message_history: List[ell.Message]) -> List[ell.Message]:
return [
ell.system("You are a helpful assistant that helps with math."),
] + message_history
With each call to the LLM (so each run of math_assistant), we will send all of
the history of the conversation. So all the previous messages returned by LLM
or Ell's tools must be included. However, let's do a very simple example first
and run it. This is a pure Python function that just calls math_assistant with
a single message. Once we run the code below we should get something like this:
def converse(initial_prompt: str):
conversation = [ ell.user(initial_prompt) ]
response: ell.Message = math_assistant(conversation)
return response.text
if __name__ == '__main__':
print(converse("What is sin(30)?"))
$ python3 sine_example.py
ToolCall(sin(angle=30.0), tool_call_id='call_LV1A18u8c38djddmns2m')
So, instead of a response by the LLM, we get an object defined in Ell because
the library decoded the response from this LLM as a request to call a tool that
is not supposed to be given back to the user. Instead of returning this, we
should check whether the latest response is ToolCall and if so, we should
execute what is requested and send the result back to the LLM for another
inference.
def converse(initial_prompt: str):
conversation = [ ell.user(initial_prompt) ]
response: ell.Message = math_assistant(conversation)
if response is ToolCall or response.tool_calls:
tool_results = response.call_tools_and_collect_as_message()
# Include what the user wanted, what the assistant requested to run, and what the tool returned
conversation = conversation + [response, tool_results]
response = math_assistant(conversation)
return response.text
if __name__ == '__main__':
print(converse("What is sin(30)?"))
Once we run it, the output for this script should be similar to the following:
$ python3 sine_example.py
The sine of 30 degrees is \( \sin(30) = 0.5 \).
However, what if we ask the model to run several sine calculations? Or
recursively run sin? Let's try this out by just changing the prompts.
if __name__ == '__main__':
print("First question: ", converse("What is sin(35) and sin(51)?"))
print("Second question: ", converse("What is sin(sin(67))?"))
$ python3 sine_example.py
First question: The values are:
- \( \sin(35^\circ) \approx 0.5735764364 \)
- \( \sin(51^\circ) \approx 0.7771459615 \)
Second question: ToolCall(sin(angle=0.9205048535), tool_call_id='call_LV1Am3HqgaPY6zhpEdR7j90m')
As you can see, for the first question the tools ran in parallel (hence
call_tools... method). However, for recursive calls, we need to implement a
loop that will run all the requested tools until there are no more requests to
run. Additionally, we should make a safeguard that will protect the model from
looping infinitely. Once we simply change if to while, the application will
start to work.
...
# The only change for now
while response is ToolCall or response.tool_calls:
tool_results = response.call_tools_and_collect_as_message()
# Include what the user wanted, what the assistant requested to run, and what the tool returned
conversation = conversation + [response, tool_results]
response = math_assistant(conversation)
...
$ python3 sine_example.py
First question: The values are as follows:
- \( \sin(35^\circ) \approx 0.5735764364 \)
- \( \sin(51^\circ) \approx 0.7771459615 \)
Second question: The value of \( \sin(\sin(67)) \) is approximately \( 0.0160651494 \).
As a safeguard we should add a variable that will count the number of loops that happened and add it to the condition. This protects us from getting charged for burning tokens for no purpose. I will give my application at most 5 loops until it will print an error.
def converse(initial_prompt: str):
conversation = [ ell.user(initial_prompt) ]
response: ell.Message = math_assistant(conversation)
max_iterations = 5
while max_iterations > 0 and (response is ToolCall or response.tool_calls):
tool_results = response.call_tools_and_collect_as_message()
# Include what the user wanted, what the assistant requsted to run and what the tool returned
conversation = conversation + [response, tool_results]
response = math_assistant(conversation)
max_iterations -= 1
if max_iterations <= 0:
raise Exception("Too many iterations, probably stuck in a loop.")
return response.text
The easiest way to test this would be to stack 6 sine calls so that the program raises an exception. Let's try doing two tests - when we just as the agent to run it three or four times and another prompt to run it six times. Depending on the mood and temperature, model will understand 🙄 and finally hit the limit.
if __name__ == '__main__':
print("First question: ", converse("What is sine of sine of sine of 10 degrees?"))
print("Second question: ", converse("What is sine of sine of sine of sine of sine of sine of 10 degrees?"))
$ python3 sine_example.py
First question: The sine of sine of sine of 10 degrees is approximately \(0.0000528962\).
Traceback (most recent call last):
File "/Users/ppabis/Ell1/sine_example.py", line 40, in <module>
print("Second question: ", converse("What is sine of sine of sine of sine of sine of sine of 10 degrees?"))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/ppabis/Ell1/sine_example.py", line 34, in converse
raise Exception("Too many iterations, probably stuck in a loop.")
Exception: Too many iterations, probably stuck in a loop.
Debugging with ell-studio
However, this example I presented you here required several runs. I decided to
record the calls using Ell's built in logging and check how the calls to the
functions looked like. I was pretty unlucky because GPT-4o-mini sometimes did
not understand how to run nested 6 sin functions recursively and instead ran
them in parallel. On the other hand the three nested calls were correctly ran
recursively.
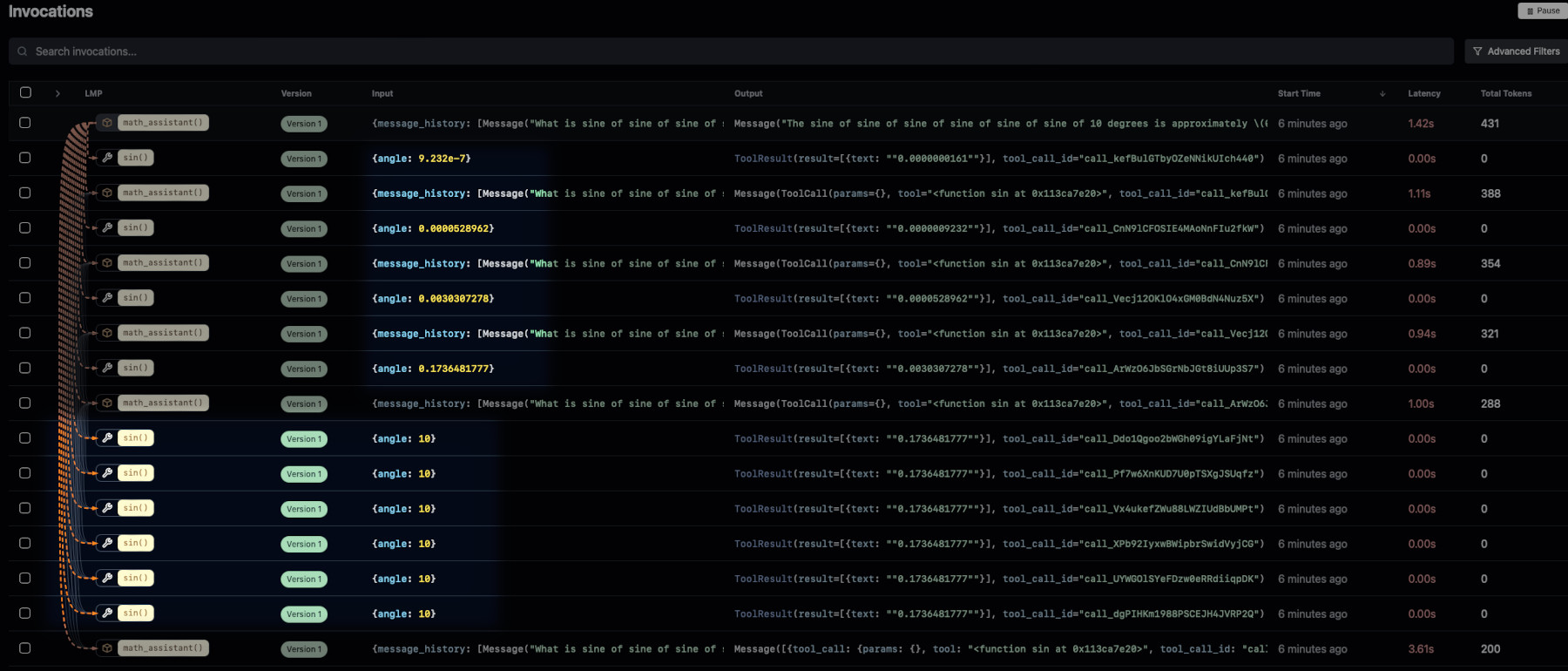
When you nest multiple calls, Ell Studio will also show dependencies between
prompts and tools as well as which output goes to which input. In our sine
example, the output of math_assistant is fed back to its input as well as
output of sin in one of math_assistant inputs (orange dashed lines). The
number next to the bolt ⚡️ also indicated how many times this function was
invoked.
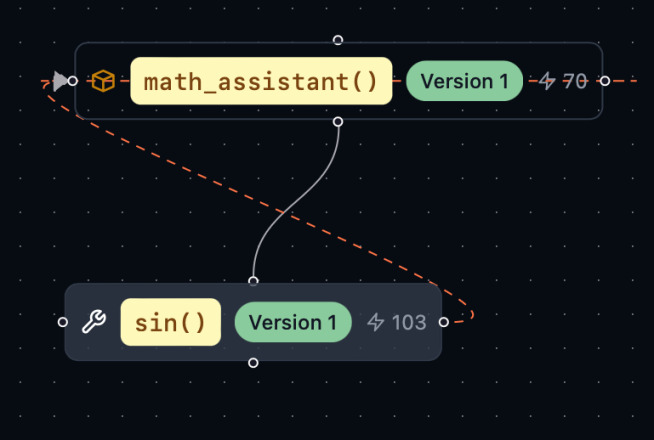
This way I was able to improve the system prompt and try it again. This time the
model was more stable but it still sometimes forgot to run one of the functions,
despite the fact I really verbosely described what it should do. gpt-4o did
understand it though.
@ell.complex(model="gpt-4o-mini", tools=[ sin ], temperature=0.8)
def math_assistant(message_history: List[ell.Message]) -> List[ell.Message]:
return [
ell.system("""You are a helpful assistant that helps with math.
Be very careful with parentheses and run tools recursively when requested.
For example if the user asks you to run f(10) and f(20) then you should use the tool f twice at once.
If the user asks you f(f(f(5))) then you should request another function or tool call when needed."""),
] + message_history
Comparator function and a test set
Technically, gpt-4o-mini already compares numbers quite well. However, we can
still improve its performance by creating a tool that will return larger,
smaller or equal based on two floats passed into the function. This way we
can ask the model to compare two numbers that will be embedded inside the sin
function or any other we come up with. I will also extract the internals of the
function so that it can be conveniently used for testing. I will also add tan
function to mix up things a bit and make them more challenging.
def _sin(angle: float) -> float:
return math.sin(math.radians(angle))
def _tan(angle: float) -> float:
return math.tan(math.radians(angle))
def _number_comparator(a: float, b: float) -> str:
if a > b:
return f"{a} is larger than {b}, {a} > {b}"
elif a < b:
return f"{a} is smaller than {b}, {a} < {b}"
else:
return f"{a} is equal to {b}, {a} = {b}"
@ell.tool()
def number_comparator(a: float = Field(description="First number 'a' to compare."),
b: float = Field(description="Second number 'b' to compare.")) -> str:
"""Returns 'larger' if a > b, 'smaller' if a < b and 'equal' if a = b."""
return _number_comparator(a, b)
@ell.tool()
def tangent(angle: float = Field(description="Angle in degrees.")) -> str:
"""Returns a value of tan(angle), which is tangent, with up 10 decimal places. For example tan(45) = 1."""
value = _tan(angle)
return f"{value:.10f}"
@ell.tool()
def sin(angle: float = Field(description="Angle in degrees.")) -> str:
"""Returns a value of sin(angle), which is sine, with up 10 decimal places. For example sin(30) = 0.5."""
value = _sin(angle)
return f"{value:.10f}"
Now we can prepare some test sets. We will print out the results of actual
values directly computed by Python and the results made by the model. Some of
the examples will be simple, others will be more complex. For each test we will
use a structure that will contain the prompt and the expected result. Instead of
hardcoding the results, we will use the extracted functions, prefixed by
underscore, so that they are not recorded by Ell's logger. Remember to also
update the math_assistant function to include the new tools.
...
@ell.complex(model="gpt-4o-mini", tools=[ sin, tangent, number_comparator ], temperature=0.8)
def math_assistant(message_history: List[ell.Message]) -> List[ell.Message]:
...
TESTS = [
{
'prompt': "Is 0.5 larger than 0.4?",
'expected': f"{_number_comparator(0.5, 0.4)}"
},
{
'prompt': "What is sin(3910)?",
'expected': f"sin(3910) = {_sin(3910):.10f}"
},
{
'prompt': "What is tan(4455)?",
'expected': f"tan(4455) = {_tan(4455):.10f}"
},
{
'prompt': "What is larger sin(sin(789)) or tan(9999)?",
'expected': f"sin(sin(789)) = {_sin(_sin(789)):.10f}, tan(9999) = {_tan(9999):.10f}, {_number_comparator(_sin(_sin(789)), _tan(9999))}"
},
{
'prompt': "What is the value of sin(tan(8910))?",
'expected': f"sin(tan(8910)) = {_sin(_tan(8910)):.10f}"
},
{
'prompt': "Is sin(8.333) larger than tan(5.45)?",
'expected': f"{_number_comparator(_sin(8.333), _tan(5.45))}"
}
]
if __name__ == '__main__':
for test in TESTS:
print(f"❓ Prompt: {test['prompt']}")
print(f"👍 Expected: {test['expected']}")
print(f"🤖 Model: {converse(test['prompt'])}")
print()
I will just print the results and let you compare if they are correct. You can
play around and call another prompt that will provide the expected result, the
output of the converse function and ask the model to semantically compare the
two if they are equal. This way you can put even more automation 😄.
I tried on gpt-4o-mini and the results were quite good but it still didn't
follow all the nested function calls. sin(tan(8910)) was computed correctly
but sin(sin(789)) was only a single sin call. Even reducing temperature did
not help.
$ python3 sine_example.py
❓ Prompt: What is larger sin(sin(789)) or tan(9999)?
👍 Expected: sin(sin(789)) = 0.0162933313, tan(9999) = -6.3137515147, 0.016293331282790816 is larger than -6.313751514675357, 0.016293331282790816 > -6.313751514675357
🤖 Model: The value of \( \sin(\sin(789)) \) is larger than \( \tan(9999) \). Specifically, \( 0.9335804265 > -6.3137515147 \).
I retried the same test on llaama-3.2-3b on Groq to see how well a small model
will behave on these tests. However, this model did not even understand how to
deal with the functions - apparently internal prompts were not good enough to
guide it through the process. Even in the first call it failed to format the
answer reasonably.
$ python3 sine_example.py
❓ Prompt: Is 0.5 larger than 0.4?
👍 Expected: 0.5 is larger than 0.4, 0.5 > 0.4
🤖 Model: number_comparator=a=0.5,b=0.4{"number_comparator": "larger"}</number_comparator>
❓ Prompt: What is sin(3910)?
👍 Expected: sin(3910) = -0.7660444431
Traceback (most recent call last):
...
openai.BadRequestError: Error code: 400 - {'error': {'message': "Failed to call a function. Please adjust your prompt. See 'failed_generation' for more details.", 'type': 'invalid_request_error', 'code': 'tool_use_failed', 'failed_generation': '<function=sin>{3910}</function>'}}
Any other standard Llama model on Groq also failed miserably or wasn't even
available (responding with 503). However,
llama3-groq-70b-8192-tool-use-preview actually worked but still made the same
mistake of calling only a single sin function instead of two nested ones, just
like gpt-4o-mini. It did not give me the intermediate values, just plain
"larger" but changing the tangent values to invert the test did not change the
result. I looked into Ell Studio and saw that two sin functions were called in
parallel.
{ "message_history": [
{ "content": [
{
"text": { "content": "What is larger sin(sin(789)) or tan(9939)? Provide all the intermediate values." }
}
],
"role": "user"
},
{ "content": [
{ "tool_call": {
"tool": "<function sin at 0x107a0eb60>",
"tool_call_id": { "content": "call_sxmq" }
}
},
{ "tool_call": {
"tool": "<function sin at 0x107a0eb60>",
"tool_call_id": { "content": "call_914c" }
}
},
{ "tool_call": {
"tool": "<function tangent at 0x107a0e3e0>",
"tool_call_id": { "content": "call_dd5a" }
}
}
],
"role": "assistant"
},
{ "content": [
{ "tool_result": {
"result": [ { "text": { "content": "\"0.9335804265\"" } } ],
"tool_call_id": { "content": "call_sxmq" }
}
},
{ "tool_result": {
"result": [ { "text": { "content": "\"0.9335804265\"" } } ],
"tool_call_id": { "content": "call_914c" }
}
},
{ "tool_result": {
"result": [ { "text": { "content": "\"0.8097840332\"" } } ],
"tool_call_id": { "content": "call_dd5a" }
}
}
],
"role": "user"
}
]}
Sorry for the weird formatting but I wanted to shorten it a bit. So these are
the three messages exchanged between our program and the model. First we send
the prompt. Then the assistant sends us back request to run the tools: two sin
functions and one tan function. Then we as the "user" send the model again the
history of all that happened before (prompt and requests to run tools) along
with the outputs of these tools.
Using different model providers
By default, Ell can use OpenAI models. Anthropic is another first-class provider in Ell. According to documentation it also supports Groq and Cohere but you still have to construct the client yourself so it is not different than any other compatible client. I decided to demonstrate Groq as it has quite generous free tier and has the fastest inference by using their own LPU hardware. Create Groq account and generate a new key here. Save it somewhere safe. Then load it into the environment. Also ensure that Groq Python packages are installed.
$ read -s GROQ_API_KEY # Paste the key after running this command
$ export GROQ_API_KEY
$ pip install groq
There are two ways to construct and pass a Groq client - either using directly
their client or OpenAI compatible endpoint. ell is compatible with both so far
but I want to demonstrate the OpenAI one as well as it can be reused for other
providers that have such API compatibility.
import os
from groq import Groq
groq_client = Groq(api_key=os.environ["GROQ_API_KEY"])
from openai import Client
groq_openai_client = Client(base_url="https://api.groq.com/openai/v1", api_key=os.environ["GROQ_API_KEY"])
@ell.simple(model="llama-3.2-3b-preview", client=groq_client)
def llama_groq():
"""You are a helpful assistant."""
return "Who are you, what's your name? What model are you? What version?"
@ell.simple(model="llama-3.2-3b-preview", client=groq_openai_client)
def llama_groq_openai():
"""You are a helpful assistant."""
return "Who are you, what's your name? What model are you? What version?"
Gaining Mastery
However, you won't learn until you experiment (or even fail sometimes 😣). The examples above give only a glimpse of what Ell does. What you use it for is a completely different story. Just as learning a new programming framework doesn't make sense if you don't use it. So, look for things that you can optimize and automate with AI Agents. Maybe port your old project you made with LangChain or Swarm (a new agent framework from OpenAI)?
Another thing you can try is embedding calls to other prompts within tools - for
example main GPT-4o wants to search through huge amounts of text documents and
it requests a tool to load the file, call GPT-4o-mini with the content of the
document and prompt to summarize. That way you can save on GPT-4o input tokens
so that it doesn't load entire documents - just summaries. This way it can
easier search through a large bunch of them.