Cut Costs in OpenSearch Serverless with Bedrock Knowledge Base
22 August 2024
One thing that grinds my gears about AWS OpenSearch Serverless is that it is "serverless". That means that despite the promise of serverless services, such as Lambda or Fargate, where you pay only for what you use, OpenSearch uses OCUs (capacity units) constantly. It's not a large amount but it can still be a pain. In today's post I want to suggest a solution that creates and destroys OpenSearch collection after Bedrock is done using it in a nightly batch job. It can also be adapted to a workday schedule. It turns out that the whole process is not as straightforward as you might think. Because of the complexity I plan to divide this post into two parts.
High-level overview
The project will be constructed of two types of resources: static ones and dynamic. Static ones will be IAM roles, S3 buckets, some CloudFormation files, a Lambda function and a Step Function. The will be there on the account until you decide to destroy them. The dynamic resources will be created by Step Function and CloudFormation and removed afterwards. Below I created a high-level overview diagram of the steps that will be conducted by the automation.
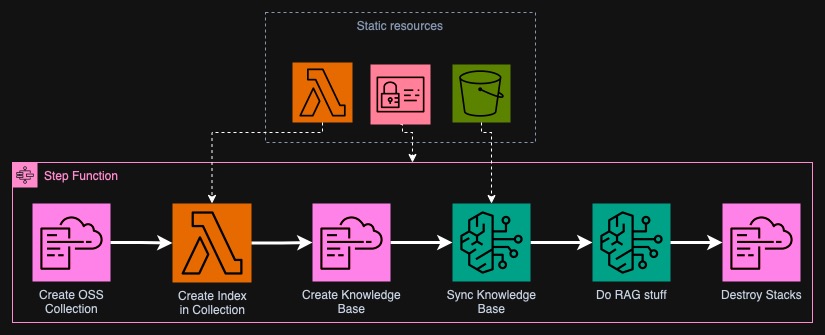
In the first step, the Step Function will create OpenSearch Serverless Collection with required policies in a CloudFormation Stack. This step is unfortunately very slow, often it takes more than 10 minutes. One thing that is required for Bedrock Knowledge Base is index in the collection. It isn't currently possible to create it using CloudFormation. We will use Lambda for this purpose.
Afterwards, another CloudFormation stack will be created with Bedrock Knowledge Base and Data Source. Next we will sync the Knowledge Base - convert all the contents of an S3 bucket into embedding vectors stored in the OSS Collection. With this we will be ready to query the Knowledge Base using a model of our choice.
In the last step, we will destroy both CloudFormation stacks to save costs. Worth to note is that if you have a lot of data in S3, it might turn out that the price of converting the files into embeddings will be higher than the price of keeping OSS running. In such case, you probably have enough cash to not care about some dollars a day because of unused OpenSearch 😅.
Alternative approaches
There are some alternative approaches to this problem that can be easier or cheaper. However, I wanted to use the default suggested tools by AWS.
The first alternative is a free tier of Pinecone. You can sign up for their vector database service and use it in Bedrock with an API key. Another one is using a custom vector database, your own embedding model and LangChain. You can run Chroma or pgvector on your own infrastructure whether it is EC2, ECS or EKS.
As for approaches in this project, the two CloudFormation templates can be replaced with a single one if you convert the Lambda function into a custom CFN resource. However, I wanted to be able to debug easily with a good overview on the Step Function graph.
Static resources
In this part of the blog I will describe all the necessary static resources that will be needed for the project. We will define IAM roles, buckets, CloudFormation templates and the Lambda function. The infrastructure is written in Terraform. The completed project is already available in this GitHub repository.
Configuring IAM roles
We need four IAM roles for this project. I will skip addition of S3 permissions to the roles as these can be also managed by the bucket policy. Also OpenSearch Collections will have its own Data Access Policy that will more granularly control which principal can do what with the data. Descriptions below will not contain the full code for brevity.
Bedrock IAM role
I based this role on the one that was generated when I created the Knowledge Base through the Console, thus I use recommended trust policy. I will let Bedrock access any OSS Collection in the account and invoke any model, as it needs it for creating embeddings.
...
data "aws_iam_policy_document" "BedrockKBPolicy" {
statement {
actions = ["bedrock:InvokeModel"]
resources = ["arn:aws:bedrock:${data.aws_region.current.name}::foundation-model/*"]
}
statement {
actions = ["aoss:APIAccessAll"]
resources = ["arn:aws:aoss:${data.aws_region.current.name}:${data.aws_caller_identity.me.account_id}:collection/*"]
}
}
...
CloudFormation IAM role
I will take a shortcut here and use just AdministratorAccess policy,
effectively giving CloudFormation absolute control over my account. The best way
would be to define minimal permissions.
...
resource "aws_iam_role" "CloudFormationRole" {
name = "CloudFormationRole"
assume_role_policy = data.aws_iam_policy_document.CloudFormationTrustPolicy.json
}
resource "aws_iam_role_policy_attachment" "CloudFormationPolicyAttachment" {
# Quite a dumb way to define a role but meh, whatever ¯\_(ツ)_/¯
role = aws_iam_role.CloudFormationRole.name
policy_arn = "arn:aws:iam::aws:policy/AdministratorAccess"
}
Full code for CloudFormation Role
Lambda IAM role
I will give full API access to Lambda on OpenSearch collection as it needs the
ability to write the index to the collection. I will also give it standard
AWSLambdaBasicExecutionRole policy to see the logs.
...
data "aws_iam_policy_document" "AllowLambdaAOSS" {
statement {
actions = ["aoss:APIAccessAll"]
resources = ["arn:aws:aoss:${data.aws_region.current.name}:${data.aws_caller_identity.me.account_id}:collection/*"]
}
}
resource "aws_iam_role_policy" "LambdaInlinePolicy" {
name = "LambdaInlinePolicy"
role = aws_iam_role.LambdaRole.name
policy = data.aws_iam_policy_document.AllowLambdaAOSS.json
}
resource "aws_iam_role_policy_attachment" "LambdaBasicExecutionRole" {
role = aws_iam_role.LambdaRole.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
}
Step Functions IAM role
Step functions needs to be able to perform CloudFormation stack creation and deletion, pass IAM role to CloudFormation and call Bedrock for both synchronizing the Knowledge Base and running inference on a chosen model. I am not sure if it doesn't also require it to have S3 access but I will define it also in the bucket policy, just in case. I will be very permissive here in terms of CloudFormation operations and Bedrock read-only ones. It will also need to run the Lambda for index creation.
...
data "aws_iam_policy_document" "StepFunctionsPolicy" {
statement {
actions = [ "cloudformation:*" ]
resources = [ "*" ]
}
statement {
actions = [ "iam:PassRole" ]
resources = [ aws_iam_role.CloudFormationRole.arn ]
condition {
test = "StringEquals"
variable = "iam:PassedToService"
values = [ "cloudformation.amazonaws.com" ]
}
}
statement {
actions = [
"bedrock:InvokeModel",
"bedrock:List*",
"bedrock:Get*",
"bedrock:StartIngestionJob",
"bedrock:Retrieve",
"bedrock:RetrieveAndGenerate"
]
resources = [ "*" ]
}
statement {
actions = [ "lambda:InvokeFunction" ]
resources = [ "${aws_lambda_function.create_index.arn}:*" ]
}
}
Full code for Step Functions Role
S3 Buckets that we need
We need three S3 buckets (or at least two). The first bucket will be used for
storing the knowledge for our model to query. Into there you will throw your
PDFs and other text files. The second bucket will contain the CloudFormation
templates so that Step Function can pass them. I also used it to store the
Lambda function .zip file as it turned out to be faster and more stable than
uploading directly from Terraform 🤔. The third bucket is optional - I store LLM
outputs in there. However, you can modify the project to save put the data into
SQS, SNS or wherever you want.
In the Terraform code I used hashicorp/random provider to generate random
suffixes for the bucket names. Each bucket has also a policy attached allowing
specific roles to read from it or write to it.
CloudFormation Templates
In order to create OpenSearch collection and Bedrock Knowledge Base easily, we will utilize CloudFormation. It would be much easier to read and maintain than using API calls from Step Functions. I will define two templates in YAML that will be stored in the S3 bucket. You can also adapt some other bucket if you have already by changing the policy and putting templates into it.
OpenSearch Collection Template
This template will create an OSS Collection along with necessary policies. You will need to specify two parameters, namely IAM roles of Bedrock and Lambda. It will also output some attributes of the created Collection.
---
# CloudFormation template for the OpenSearch Collection
AWSTemplateFormatVersion: '2010-09-09'
Description: OpenSearch Collection for our Knowledge Base
# Inputs needed for the template
Parameters:
BedrockRoleArn:
Type: String
Description: ARN of the Bedrock KB role
LambdaRoleArn:
Type: String
Description: ARN of the Lambda role that will create index
# Outputs that we will use later passing it to next steps
Outputs:
CollectionArn:
Description: ARN of the OpenSearch Collection
Value: !GetAtt VectorCollection.Arn
CollectionEndpoint:
Description: Endpoint of the OpenSearch Collection
Value: !GetAtt VectorCollection.CollectionEndpoint
CollectionId:
Description: ID of the OpenSearch Collection
Value: !Ref VectorCollection
Resources:
VectorCollection:
Type: AWS::OpenSearchServerless::Collection
Properties:
Name: !Sub "${AWS::StackName}-collection"
StandbyReplicas: DISABLED
Type: VECTORSEARCH
DependsOn: EncryptionPolicy
...
I somewhat hardcoded the policies in JSON and only replaces the needed values of
IAM roles' ARNs in the access policy. I also hardcoded the name of the
collection in each policy because for whatever reason it cannot be retrieved
back from the collection resource. I have no idea why the policies use natural
names in resource blocks but the generated vector collection is a random string
of alphanumeric characters. Below I attach the completed policies. What is worth
noting is that the encryption policy has to be created before the collection
(unless you already have a policy with * in OSS in your account).
...
Resources:
...
AccessPolicy:
Type: AWS::OpenSearchServerless::AccessPolicy
Properties:
Name: !Sub "${AWS::StackName}-access"
Type: data
Policy:
!Sub >-
[{
"Principal": [
"${BedrockRoleArn}",
"${LambdaRoleArn}"
],
"Rules":
[
{
"Resource": [ "collection/${AWS::StackName}-collection" ],
"Permission": [
"aoss:DescribeCollectionItems",
"aoss:CreateCollectionItems",
"aoss:UpdateCollectionItems"
],
"ResourceType": "collection"
},
{
"Resource": [ "index/${AWS::StackName}-collection/*" ],
"Permission": [
"aoss:UpdateIndex",
"aoss:DescribeIndex",
"aoss:ReadDocument",
"aoss:WriteDocument",
"aoss:CreateIndex"
],
"ResourceType": "index"
}
]
}]
EncryptionPolicy:
Type: AWS::OpenSearchServerless::SecurityPolicy
Properties:
Name: !Sub "${AWS::StackName}-encryption"
Type: encryption
# It cannot reference VectorCollection as the collection depends on an encryption policy
# in the first place. So, we have to hardcode the collection name here.
Policy: !Sub >-
{"Rules":[{
"ResourceType": "collection",
"Resource": [ "collection/${AWS::StackName}-collection" ]
}],
"AWSOwnedKey": true
}
NetworkPolicy:
Type: AWS::OpenSearchServerless::SecurityPolicy
Properties:
Name: !Sub "${AWS::StackName}-network"
Type: network
Policy: !Sub >-
[{ "Rules": [
{
"Resource": [ "collection/${AWS::StackName}-collection" ],
"ResourceType": "dashboard"
},
{
"Resource": [ "collection/${AWS::StackName}-collection" ],
"ResourceType": "collection"
}
],
"AllowFromPublic": true
}
]
Code for the complete template
Knowledge Base Template
The second template is for the Bedrock Knowledge Base and Data Source. It needs a lot of parameters (unless you decide to hardcode most of the values). Here we need to pass:
- ARN of the Bedrock role,
- ARN of the embedding model,
- ARN of the OpenSearch Collection,
- Name of the S3 bucket with the knowledge base,
- Names of the fields in the index that will store the embeddings,
- Name of the above index.
You are free to change the names of the index or the fields as long as it
matches in each step. I used mykbvectorindex for the index name and
bedrock-meta, embedding and chunk for the fields.
In return we will get the Knowledge Base ID and the Data Source ID - these will be later needed for syncing the Knowledge Base and doing the RAG inference. The resources created are the following:
...
Resources:
KnowledgeBase:
Type: AWS::Bedrock::KnowledgeBase
Properties:
Name: !Sub "${AWS::StackName}-knowledge-base"
RoleArn: !Ref BedrockRoleArn
KnowledgeBaseConfiguration:
Type: VECTOR
VectorKnowledgeBaseConfiguration:
EmbeddingModelArn: !Ref EmbeddingModelArn
StorageConfiguration:
Type: OPENSEARCH_SERVERLESS
OpensearchServerlessConfiguration:
CollectionArn: !Ref VectorCollectionArn
VectorIndexName: !Ref VectorIndexName
FieldMapping:
MetadataField: !Ref MetadataFieldName
VectorField: !Ref VectorFieldName
TextField: !Ref TextFieldName
DataSource:
Type: AWS::Bedrock::DataSource
Properties:
Name: !Sub "${AWS::StackName}-DataSource"
KnowledgeBaseId: !Ref KnowledgeBase
DataDeletionPolicy: RETAIN # Helps in case the OpenSearch collection is deleted before this
DataSourceConfiguration:
Type: S3
S3Configuration:
BucketArn: !Sub "arn:aws:s3:::${KnowledgeBucket}"
Both of the templates will be uploaded to the S3 bucket. I will use Terraform resources for this and use a hash so that in case you change them, another apply will automatically pick up the changes.
resource "aws_s3_object" "CollectionTemplate" {
bucket = aws_s3_bucket.CloudFormationTemplates.bucket
key = "collection.yml"
content_base64 = filebase64("${path.module}/cloudformation/collection.yml")
source_hash = filemd5("${path.module}/cloudformation/collection.yml") # will help with the object updates
}
resource "aws_s3_object" "KnowledgeBaseTemplate" {
bucket = aws_s3_bucket.CloudFormationTemplates.bucket
key = "knowledge-base.yml"
content_base64 = filebase64("${path.module}/cloudformation/knowledge-base.yml")
source_hash = filemd5("${path.module}/cloudformation/knowledge-base.yml") # will help with the object updates
}
Lambda function for index creation
As we can't just create the index using CloudFormation, we need to use a Lambda
function (most optimally). I used Python along with opensearch-py and
requests-aws4auth libraries. Because it is Lambda, you need to put the
dependencies into the zip file (or use layers or SAM to automate this). As I
use Mac and Lambda runs on Linux, I will use Docker to get the appropriate
packages. Afaik, there are no binaries so the files should be the same but
it's safer to do it this way. If you are running Linux, you are in luck.
I placed my Lambda function in the lambda directory. On Linux simply run
pip install opensearch-py requests-aws4auth --target lambda. With Docker you
can do it like this by mounting the directory:
docker run --rm -it\
-v $(pwd)/lambda:/tmp/pip \
-u $(id -u) \
python:3.12 \
pip install opensearch-py requests-aws4auth \
--target /tmp/pip
If you use the GitHub repository, you need to perform this step before applying the infrastructure as I didn't push the libraries into the repo.
The body of the function is pretty long, so I won't post the entire code here. You can find it in the repository.
First we will create global variable with authentication tokens that will be used later for the OpenSearch client.
# ... imports
# Setup AWS credentials that can be passed later to OpenSearch endpoint
Credentials = boto3.Session().get_credentials()
AwsAuth = AWS4Auth(
Credentials.access_key,
Credentials.secret_key,
os.environ['AWS_DEFAULT_REGION'],
'aoss',
session_token=Credentials.token
)
The handler will get the parameters from the event and create the index within
the collection. I used a helper function create_vector_index that based on the
parameters just outputs a JSON string with index configuration. Next we will use
the OpenSearch client to create the index. As this is not an AWS library, we
need to point it to use IAM authentication by specifying http_auth.
If the index was created successfully, the response should contain
acknowledged field. Based on the Lambda return value (status code) we will
decide if this step was a success (200).
def create_vector_index(vectorName, dimensions, textName, metadataName):
"""
Creates an index compatible with Bedrock Knowledge Base.
"""
# ... Omitted for brevity
def lambda_handler(event, context):
# Create a request for new index creation
data = create_vector_index(event['vectorName'], event['vectorDimensions'], event['textName'], event['metadataName'])
# Step Functions pass state doesn't work as expected by data flow simulator 🤔 as it outputs a list instead of a single value
aossEndpoint = event['aossEndpoint'][0] if isinstance(event['aossEndpoint'], list) else event['aossEndpoint']
endpoint = aossEndpoint.replace('https://', '')
indexName = event['vectorIndexName']
# Create AOSS client
client = OpenSearch(
hosts=[{'host': endpoint, 'port': 443}],
http_auth=AwsAuth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection,
timeout=300
)
response = client.indices.create(index=indexName, body=data)
pprint(response)
get_index = client.indices.get(index=indexName)
pprint(get_index)
# Return the response from the API directly into Lambda
if 'acknowledged' in response and response['acknowledged']:
return {
'statusCode': 200,
'body': json.dumps(response)
}
else:
return {
'statusCode': 500,
'body': json.dumps(response)
}
The code along with the libraries should be zipped and uploaded. I used S3
bucket but it's possible to upload it directly in the aws_lambda_function
resource. However, in my case, S3 upload seemed much faster.
data "archive_file" "lambda" {
type = "zip"
source_dir = "${path.module}/lambda"
output_path = "${path.module}/lambda.zip"
}
resource "aws_s3_object" "lambda" {
bucket = aws_s3_bucket.CloudFormationTemplates.bucket
key = "lambda.zip"
source = data.archive_file.lambda.output_path
source_hash = data.archive_file.lambda.output_base64sha256
}
resource "aws_lambda_function" "create_index" {
function_name = "CreateIndexVector"
s3_bucket = aws_s3_bucket.CloudFormationTemplates.bucket
s3_key = aws_s3_object.lambda.key
s3_object_version = aws_s3_object.lambda.version_id
# Uncomment below, and comment three above to upload directly
# filename = data.archive_file.lambda.output_path
source_code_hash = data.archive_file.lambda.output_base64sha256
handler = "lambda_function.lambda_handler"
runtime = "python3.12"
role = aws_iam_role.LambdaRole.arn
timeout = 60
memory_size = 128
}
Going further
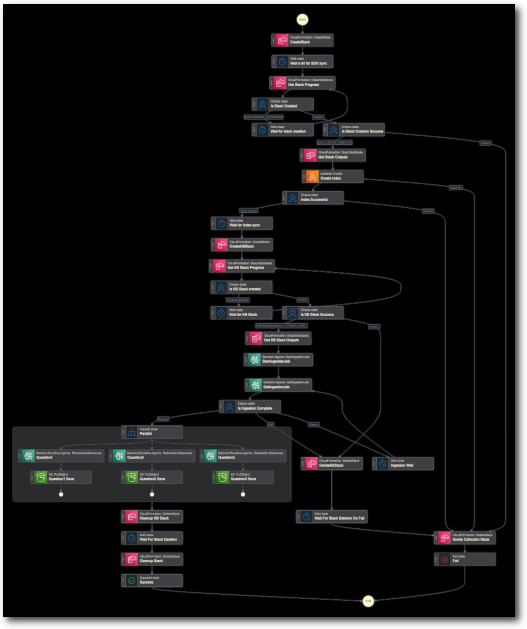
In the next part of the project, I will describe the whole process of gluing all these parts together in a Step Function. This will require a lot of explaining because... Well just see by yourself: