Cut Costs in OpenSearch Serverless with Bedrock Knowledge Base - Part 2
26 August 2024
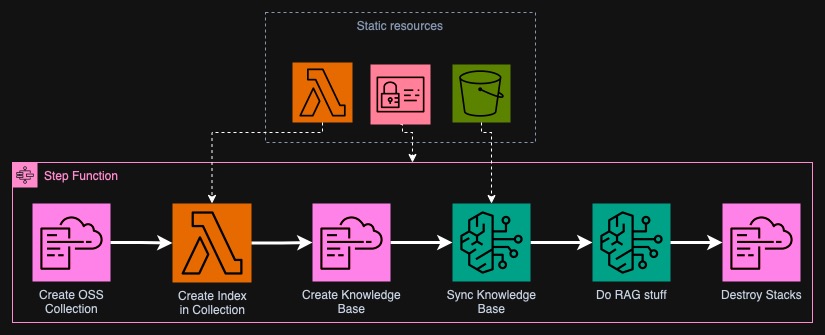
In the last post, we constructed all the necessary resources to create a Bedrock Knowledge Base utilizing OpenSearch Serverless. These were the CloudFormation templates, Lambda function for index creation and other static things like IAM Roles and S3 Buckets. Today, we will go through the process of combining all these resources to create a fully functioning "pipeline". We will use Step Functions for this.
Previous post can be found here
Let's look again at the high-level overview of the graph from the previous post. We see that we need to run some steps one by one. However, this won't map one-to-one in the Step Function. For example, we will need for the CloudFormation stack to be created and to do this, we need to periodically poll the status of the stack creation. What's more we need to handle failures so that already created resources get deleted in case something fails at a later stage.
The Step Function resulting from all the steps is thus very long. I won't paste
the entire code here. Also what is worth noting is that I decided to hardcode
some of the values inside it using Terraform's templatefile. The complexity is
already high enough so let's make it easier for us to experiment. Feel free to
modify it so that your Step Function accepts parameters.
The Step Function
I exported this graph from AWS Console. I marked how each part maps to the high-level overview. The graph is so large that AWS Console renderer doesn't know how to display it properly.
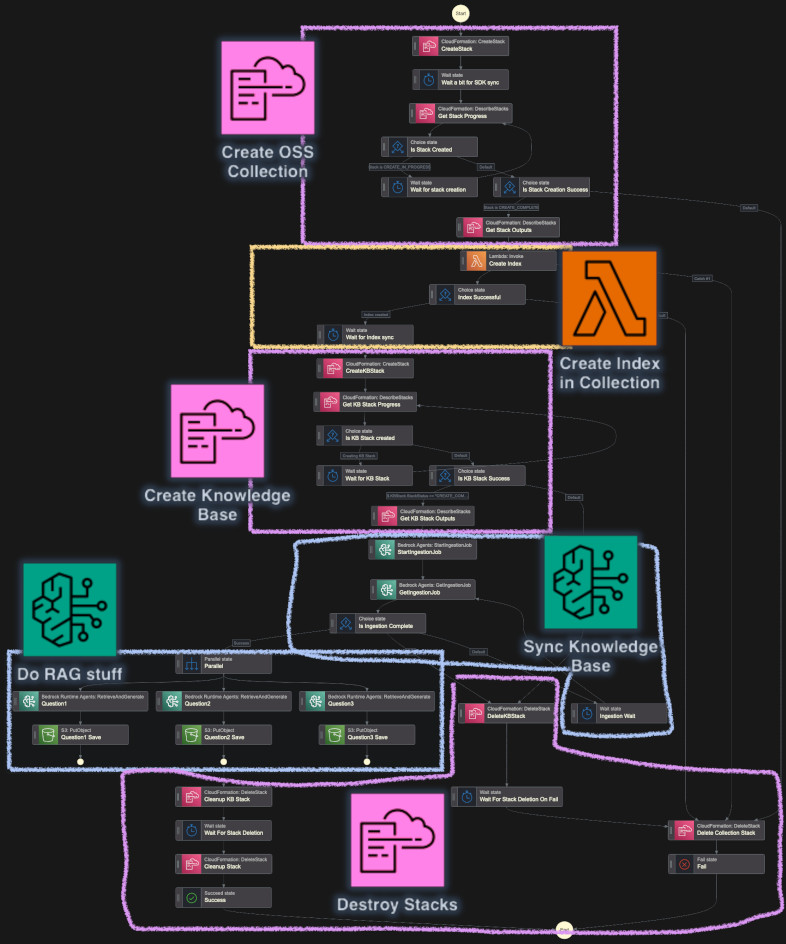
The graph above is a bit more complicated version of the step function marked as
v1. However, after writing this entire post, I simplified it and made a new
v2 version. It works the same but the choice blocks for CloudFormation stacks
are merged.
Version 2 of the Step Function Version 1 of the Step Function
Create OpenSearch Collection
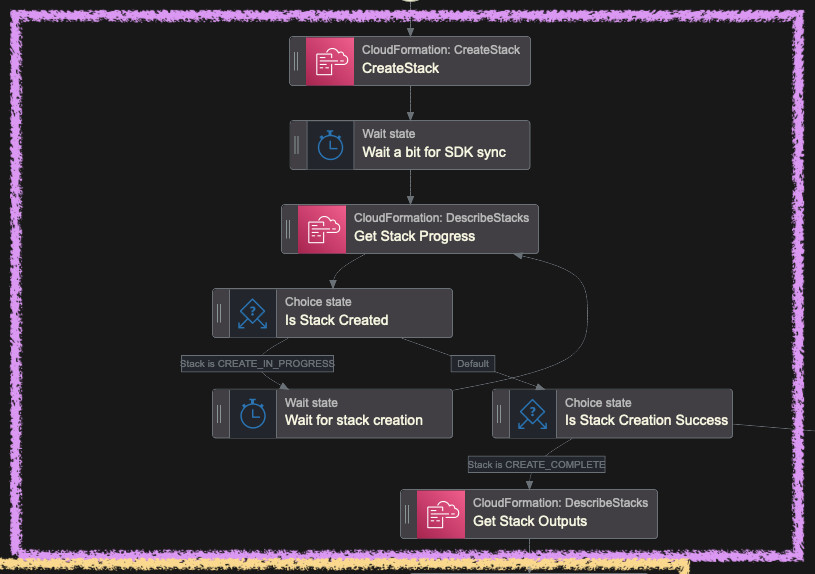
Let's go step by step through all the regions selected. First we'll create the
OpenSearch Collection. We create the CloudFormation stack with needed parameters
(LambdaRoleArn and BedrockRoleArn) and as a template we specify the URL of
the uploaded file earlier to the S3 bucket. We also give CloudFormation the IAM
role to assume. CreateStack call returns an ID that we use to poll the
progress of stack creation. If stack status is still CREATE_IN_PROGRESS we
wait for 30 seconds and call DescribeStacks again. If the status changes, we
check if it was successful with CREATE_COMPLETE. If not, we delete this stack
and fail the execution.
At the end of the step, I transform the output with ResultSelector. In order
to reach the values from the CloudFormation Outputs, you need to use a
sophisticated JsonPath expression.
{
"DataSource.$": "$.Stacks[0]..Outputs[?(@.OutputKey==DataSource)].OutputValue",
"KnowledgeBase.$": "$.Stacks[0]..Outputs[?(@.OutputKey==KnowledgeBase)].OutputValue"
}
I also appended output of each meaningful step with ResultPath so that we
don't lose any information during pipeline execution. After all, we will need
these values even when something fails in order to delete the stacks. This
block's output is saved under $.CollectionStack, so
$.CollectionStack.StackId refers to the stack with OpenSearch Collection.
Stack with the knowledge base will be stored under $.KBStack.StackId.
Create OpenSearch Index
Because there's so far no CloudFormation resource to create an index in an OSS
Collection, we need to use an HTTP call to the endpoint returned as the output
from the previous stack (CollectionEndpoint). The easiest way is to use a
Lambda function that will use OpenSearch client for Python. We prepared this
function in the previous part of this project. This function simply
authenticates with Lambda's IAM Role credentials against the endpoint and
creates an index that is appropriately formatted. We pass necessary parameters
to Lambda's event. These are vectorIndexName - which is the name of our index,
field names: vectorName, textName and metadataName; and
vectorDimensions - check
this guide
to find dimensions for your embedding model.
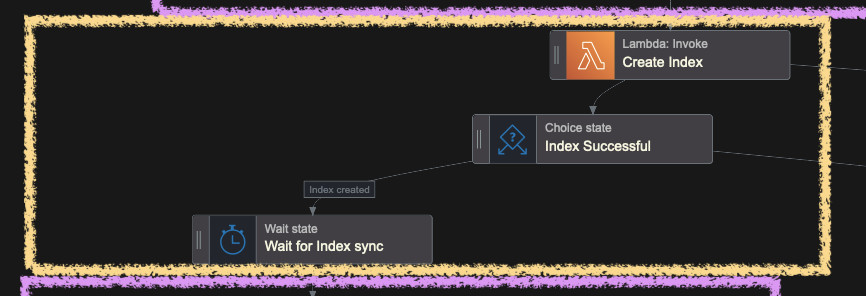
If the index creation function is successful, so if it returns 200 as status
code, we assume that the index was created. I added a small wait time to let is
synchronize between shards in OpenSearch. I found out that sometimes it's
immediate and sometimes it takes even a minute to be done. I saved output of
the Lambda function under ResultPath of $.LambdaResult.
Create Bedrock Knowledge Base
Now as we have both the collection and index inside it, we can create the
Knowledge Base in Bedrock. We define two resources in CloudFormation which are
the knowledge base itself as well as data source pointing to our S3 bucket. We
give almost all of the same parameters as we did to the Lambda function (field
names, index name) as well as ARNs of the embedding models, OpenSearch
Collection, IAM role for Bedrock and name of the S3 bucket with the knowledge.
As an embedding model, I chose Cohere Multilingual
(arn:aws:bedrock:us-west-2::foundation-model/cohere.embed-multilingual-v3)
which costs a bit but seems to be performant as well. You need to request access
to it via Bedrock Console - see
this guide.
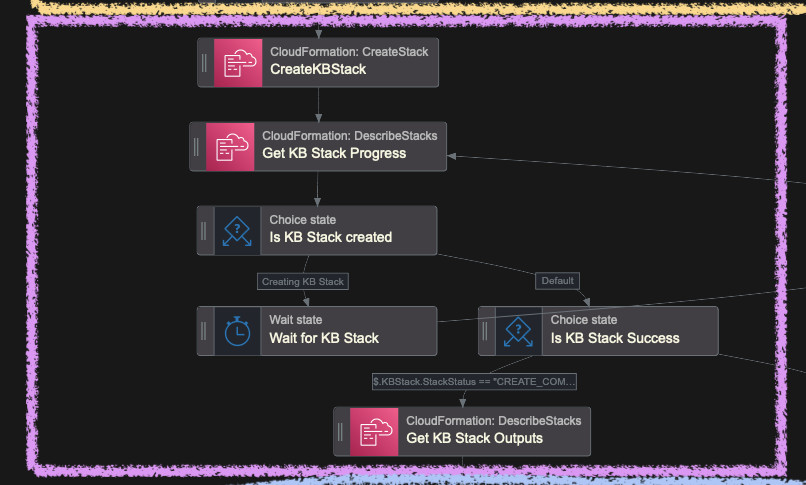
I repeated the same steps as for the first CloudFormation stack we created but this time I only wait 10 seconds. Creating a Knowledge Base should be fast.
Outputs of this stack are also transformed with ResultPath. In the next step
you will need to reference them with [0] index as for whatever reason, the
JsonPath produces an array with one element. As you can see the ResultPath of
this block is $.KBStackOutputs and $.KBStack.
{
"DataSourceId.$": "$.KBStackOutputs.DataSource[0]",
"KnowledgeBaseId.$": "$.KBStackOutputs.KnowledgeBase[0]"
}
Syncing the Knowledge Base
Now we can sync the Knowledge Base with the Data Source which is out S3 bucket. Put some files into this S3 bucket. I for example added some PDFs: Certified Machine Learning Associate and Specialty exam guides and complete EC2 User Guide in PDF format. In total it is around 32 MB.
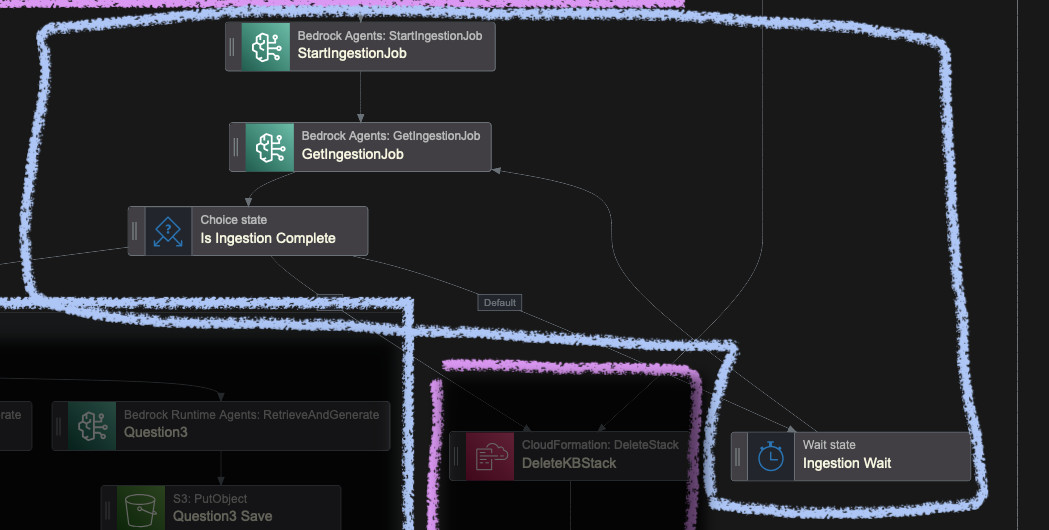
The synchronization happens when you call StartIngestionJob. It will return an
ID that you need to reference afterwards in GetIngestionJob. You then have to
poll it until it's done and the status changes to either COMPLETE or FAILED.
If it fails, we can destroy both stacks we created previously. The ResultPath
for this block is saved in $.IngestionJob.
I also wait with polling in this case for 30 seconds as it can take a long time. Depending on the amount of data you put into the S3 bucket and the embedding model you choose, this step can be the most expensive one in this project.
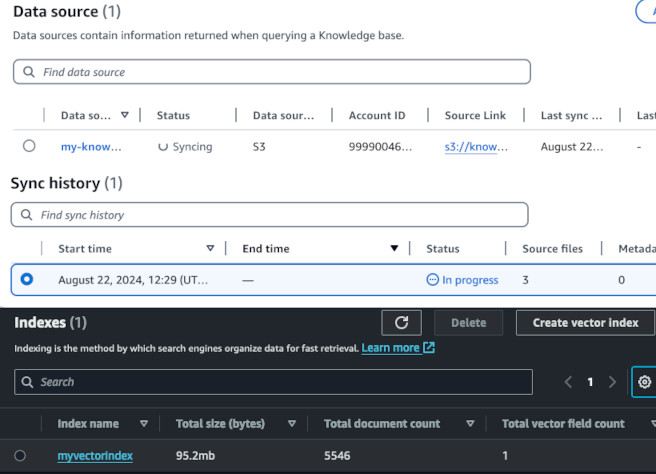
I observed the synchronization process. In the end it produced 95 MB of indexed chunks of text and took 8 minutes to complete.
Performing RAG Inference
Now you have a fully functioning Knowledge Base. It's your choice now if you
want to use it immediately for performing a batch inference or if you want to
create a Wait step, for example until specified date such as 5PM of today so
that this Knowledge Base can be used whenever needed by your team. In my example
I just do some queries to Claude 3 Haiku.
Before I created all the queries, I wanted to test if the knowledge base is even
usable by the LLM. So, I paused the execution of the Step Function by removing
the DeleteStack steps and used Bedrock's Console to test it. I found this
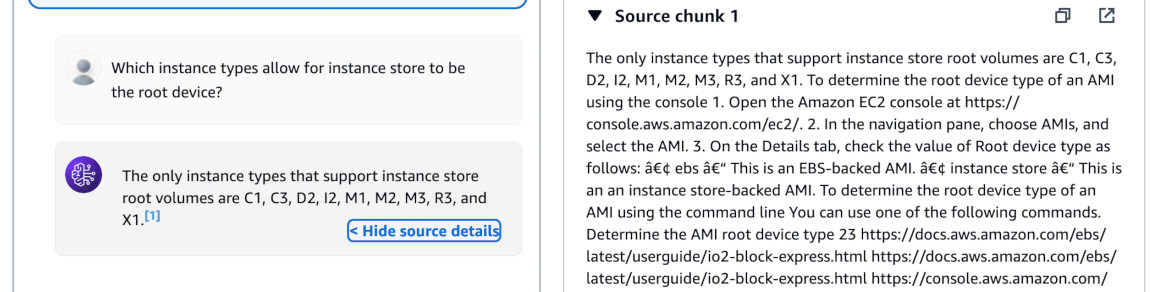
interesting frame in EC2 User Guide about instance store as the root device.

First, I asked clean Haiku in the Chat Playground to see if it maybe knows it internally. Fortunately (or not), the answer was far from the truth. It hallucinated the instance types. I used temperature of 0.7 and top P of 0.9.
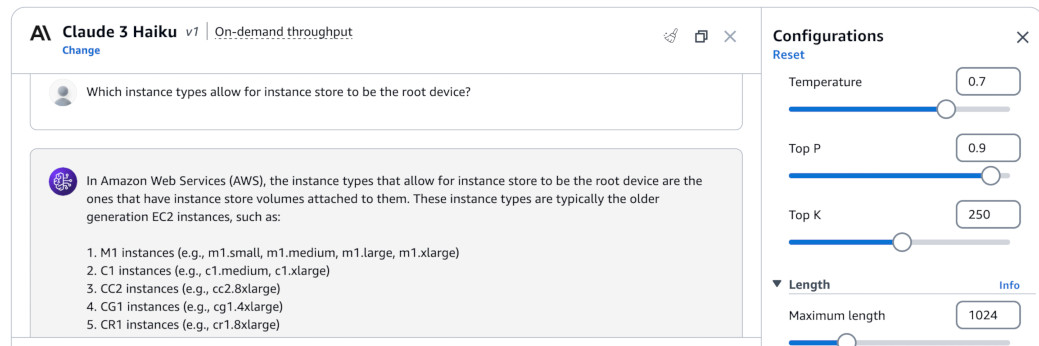
With the same settings of temperature = 0.7 and top P = 0.9, I asked Haiku in
RAG loop (using Test knowledge base button) the same question. It answered
correctly and gave the reference in my S3 bucket.
Because the answer was promising, I created a set of queries to run in parallel in the Step Function. Each of the questions I put into S3 bucket as JSONs returned from Bedrock, which includes both the response and references from the Knowledge Base.
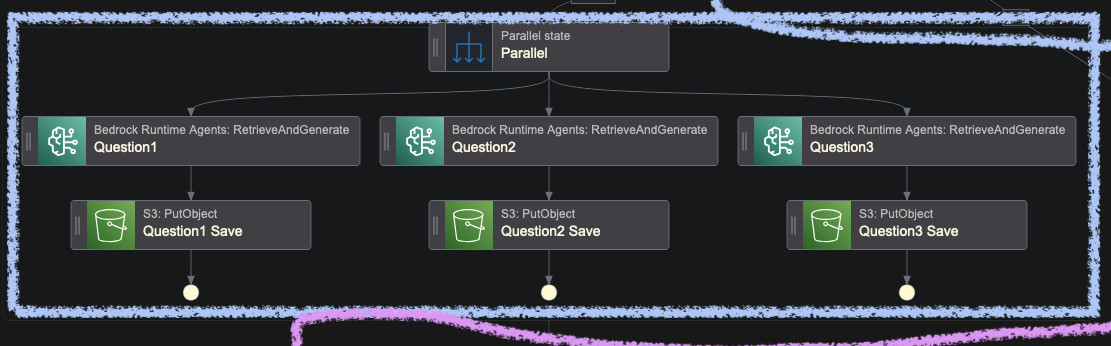
In order for the object keys to be unique in the bucket, I added a time and date
retrieved from Step Functions context ($$) along with States.Format
function. So the configuration of the PutObject call looks like this:
{
"Body.$": "$.RAGResult",
"Bucket": "my-outputs-abcdef12",
"Key.$": "States.Format('ec2_discount/{}.json', $$.State.EnteredTime)"
}
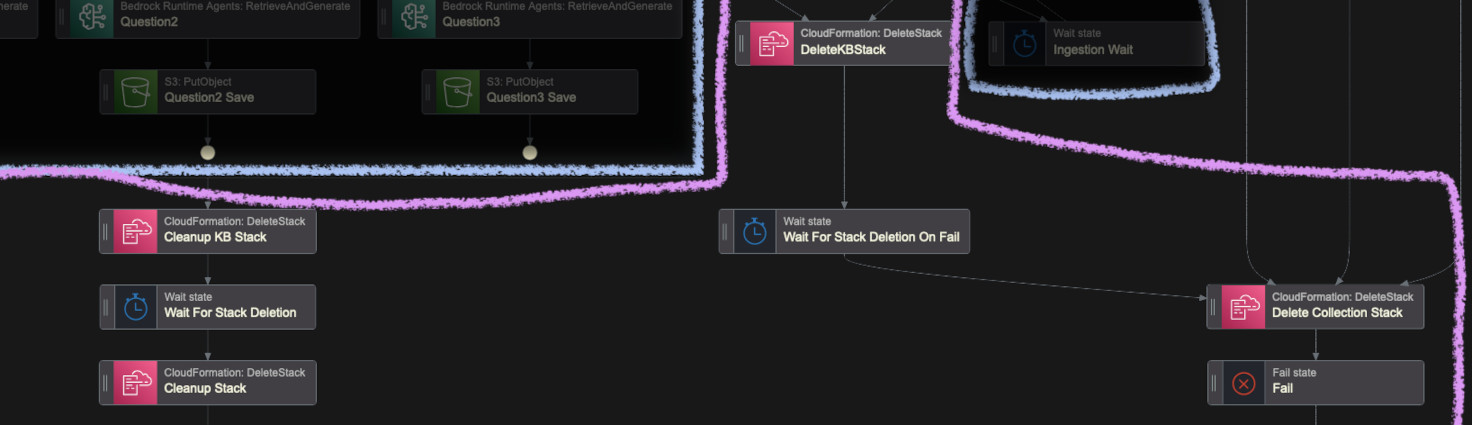
Cleanup
After all queries are done, we can delete all the stacks we created in order to save on costs. Deleting the knowledge base should be the first one as it depends on the collection. The section below also includes the deletion of stacks in case of failures along the way. However, I want to note that not all of the failure scenarios are covered, so you might need to adjust it for more cases, as it can lead to the OpenSearch Collection running without being used.
Costs
I tested how much does it cost to run this pipeline versus having the OpenSearch Collection created for a day. On August 25th I ran the pipeline without doing anything else on this AWS account. On the same day, I created an empty OpenSearch Collection in a different account at 4PM and let it run for 24 hours.
The single run of the step function cost me $0.25 - this includes running OSS, converting text to embeddings using Cohere and Haiku inference itself. On the other account, where I left an empty OpenSearch Collection running for somewhat less than 24 hours I got bill for $2.94.
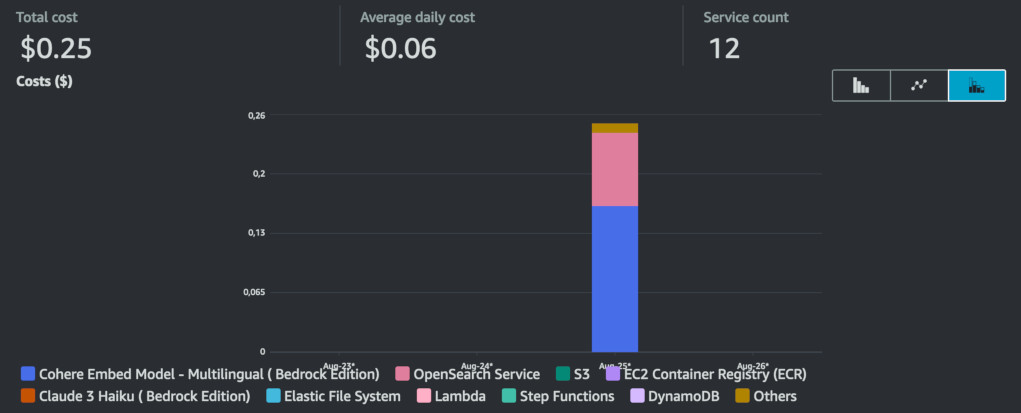
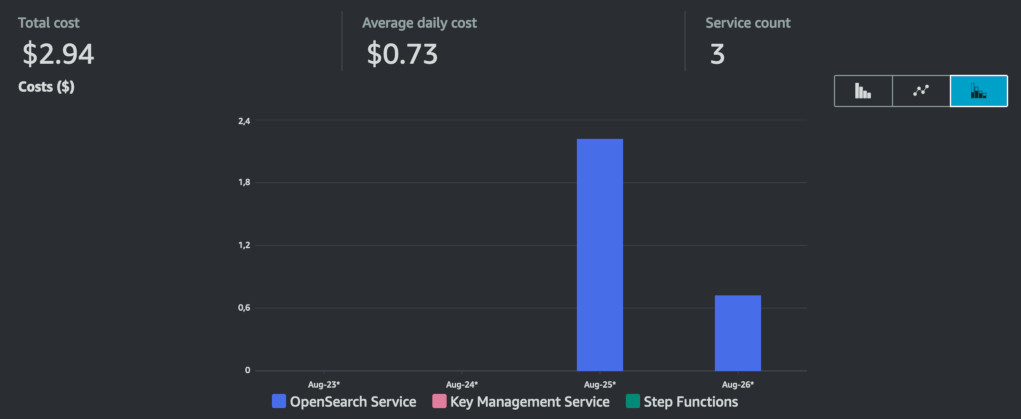
The largest cost for the pipeline was as expected synchronization between S3 and the index. Cohere cost me $0.16 for this single run. This price can be reduced if we use cheaper model such as Cohere English or Amazon Titan. However, if you plan to scan gigabytes of data, it can be more reasonable to have the OpenSearch Collection running. As on screenshot in "Syncing the Knowledge Base" section, my index resulted in size of 95 MB.
Improvements
While describing this process I found some places where the function can be
improved, so I did just that. The new function is named
step-function-v2.yaml
and can be found in the repository. You can select it when deploying with
OpenTofu by changing the variable step_function_ver to v2.
I simplified and cleaned up the outputs so that each block has it's own
ResultPath instead of mixing all the values together. I also merged choice
statements so that they don't have only two choices, but three - for success,
for "in progress" and any other status of the CloudFormation stack - for example
Is KB Stack Created and Is KB Stack Success is now a one choice step.